

NOTE: I STARTED USING AI TO GENERATE LESSONS REAL TIME IN CLASS.
THIS IS AN EXAMPLE OF AN AI-GENERATED LESSON DONE LIVE IN CLASS
What you are about to read was not written before class. It was written during class—generated live, in front of students, as a demonstration of the very technology it describes.
That matters. Not as a parlor trick, but as a pedagogical choice. The lesson concerns how language models actually produce output: not by retrieving stored answers, not by reasoning the way a human reasons, but by drawing—probabilistically, one word at a time—from a shaped distribution of possibilities. The best way to teach that is to show it happening.
The document uses a single recurring experiment as its spine: ask an AI whether Wonder Woman’s box office gross could buy a Boeing 737. Ask it once at low temperature. Ask it again. Ask it a third time with the randomness dial turned up. Watch what changes and what doesn’t. That progression—from reliable to drifting to strange—is the lesson. Everything else is explanation.
What follows covers the mathematics of token sampling (the softmax function, temperature scaling, entropy), the practical mechanics of Top-K and Top-P truncation, the phenomenon of Expert Default Bias (why AI personas change their tone but rarely their logic), and the emerging design space of agentic systems that treat sampling parameters as a feedback loop rather than a fixed setting.
Six exercises close the document. Each is designed to be run with an AI assistant—Claude, GPT-4o, or equivalent—so the tool you are learning about becomes the tool you use to learn.
This is what it looks like when a classroom generates its own materials in real time. The content is rigorous. The method is the message.
Tags: LLM temperature sampling, language model probability, softmax token generation, agentic AI feedback loops, few-shot exemplar selection
You ask a language model whether Wonder Woman’s 2017 box office gross could buy a Boeing 737. The answer comes back instantly, confident, grammatically immaculate: Yes, at approximately $822 million, the film’s receipts comfortably exceed the $90–$115 million cost of a standard 737.
Now ask again. Same question. Same model. Different session.
The answer comes back again. Still correct. Still confident. Slightly different phrasing, maybe a detail about director Patty Jenkins, maybe a specification of the 737 MAX variant.
Ask a third time, but this time you’ve turned a dial—one you probably didn’t know existed—toward its upper limit.
This time, the answer drifts. Bizarro Wonder Woman appears somewhere. The Justice League is mentioned. The logical chain between box office receipts and aircraft costs starts to loosen, and you begin to suspect the model has forgotten what it was being asked.
Same model. Same question. Three different answers.
This is not a glitch. This is the machine working exactly as designed.
Here is the thing most people get wrong about language models: they treat them like search engines with better grammar. It retrieved the answer. It stored the fact. It found the quote.
That framing is wrong in a precise, measurable, consequential way.
In standard inference, an LLM does not retrieve a stored response. It generates a sequence one token at a time, making a probabilistic choice at each step about what comes next. The mathematical statement is compact but carries enormous weight:
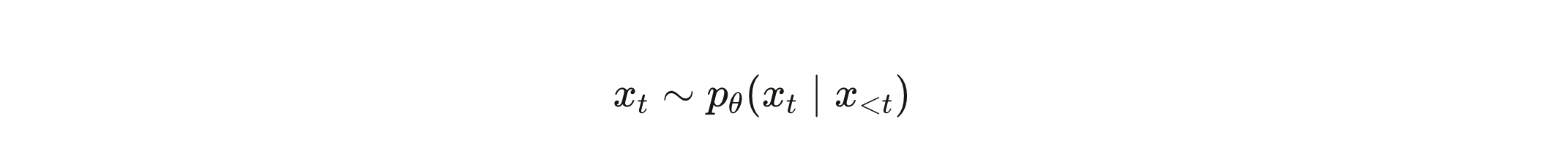
xt is the next token. x<tx_{<t} x<t is everything that came before—your entire prompt, every word already generated. pθp_\theta pθ is a probability distribution shaped by the model’s learned weights. And the ∼\sim ∼ symbol is the most important character in that equation. It means *sampled from*. Not *equal to*. Not *retrieved from*. Sampled from.
The output is a draw. Every time.
Even when you see the same answer twice, you are not seeing retrieval. You are seeing a distribution so sharply peaked that the same token wins the draw twice. The moment you push that distribution toward flatness—toward equal probability across many options—the draw starts landing somewhere new.
To understand how that distribution gets shaped, you need to follow the math one step further.
At each generation step, the model produces a vector of raw numbers—one number per word in its vocabulary, which for modern models means tens of thousands of numbers. These are called logits. A logit of 8.3 for the token “Boeing” and 2.1 for the token “airplane” doesn’t mean the model is 8.3% confident in one and 2.1% in the other. Logits aren’t probabilities. They’re scores. To convert them into something you can sample from, you apply the softmax function:
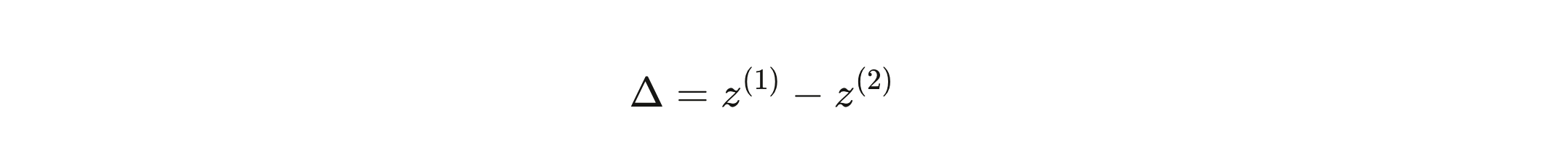
Two things happen inside this equation that matter enormously.
First, only differences between logits matter. Add 100 to every number in the vector and the probabilities don’t change. The distribution is about relative standing, not absolute value.
Second, a single token can dominate. If one logit is significantly higher than all others, the exponential function amplifies that gap dramatically. The token with the highest logit absorbs most of the probability mass. The distribution becomes a spike.
The gap between the top two logits—call it Δ=z(1)−z(2)\Delta = z^{(1)} - z^{(2)} Δ=z(1)−z(2)—is your informal confidence meter. Large Δ\Delta Δ means the model is decisive: this token, almost certainly, and here is why. Small Δ\Delta Δ means it’s genuinely uncertain: any of three or four tokens could come next, and which one does is close to a coin flip.
That spike—or that coin flip—is what temperature controls.
Temperature T is a single number, but it reshapes the entire distribution:
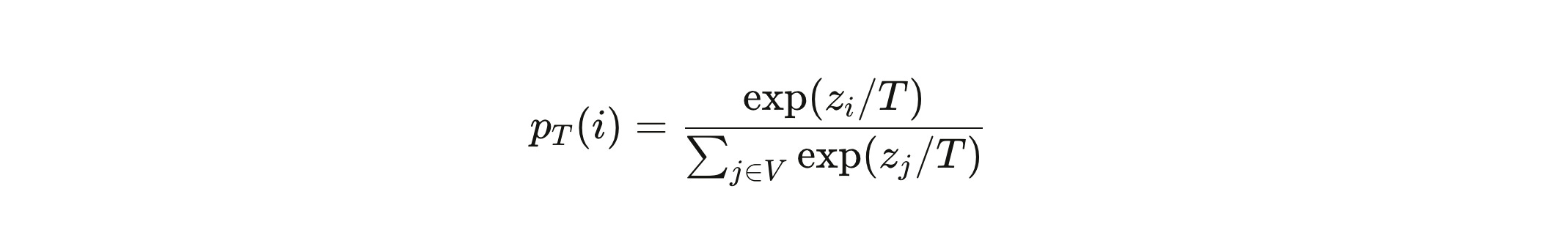
When T<1, you divide the logits by a number less than one, which means you *increase* the gaps between them. The distribution sharpens. The most likely token becomes even more dominant. Set T close to zero and you’ve essentially eliminated randomness: the model picks the highest-scoring token every single time. This is called greedy decoding, and it’s what most people imagine when they think about a “correct” AI answer.
When T>1, you divide by a large number, shrinking the gaps. The distribution flattens. Tokens that had small logits get relatively larger. Tokens that had large logits lose their dominance. You start sampling from the long tail—the weird, the unexpected, the sometimes inspired, the sometimes incoherent.
This flattening is measurable. The formal tool is entropy:
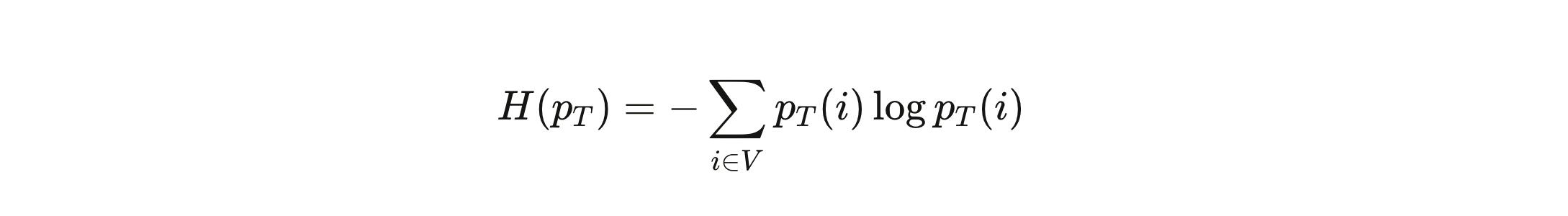
High entropy means the distribution is spread out—many tokens have non-negligible probability. Low entropy means it’s concentrated. As temperature rises, entropy rises with it. As entropy rises, output variance rises with it. The model starts generating completions that differ not just in phrasing but in substance.
This is exactly what you see in the Wonder Woman experiment. At T=0T = 0 T=0, the model locks onto the canonical facts. At T=0.7T = 0.7 T=0.7, it stays accurate but starts varying the framing—different emphasis, different supporting details. At T=1.2T = 1.2 T=1.2, it begins sampling from tokens that are plausible in some loose semantic sense but no longer reliably anchored to the factual core. The box office number drifts. The aircraft cost gets fuzzy. *Bizarro Wonder Woman* enters the frame.
Temperature reshapes the whole distribution. But sometimes you don’t want to reshape—you want to truncate. That’s what Top-K and Top-P sampling do.
Top-K keeps only the K most probable tokens and throws the rest away. If K=50, you never sample from the bottom 99.9% of the vocabulary. The tail is gone. You renormalize across those 50 tokens and sample from that restricted set:
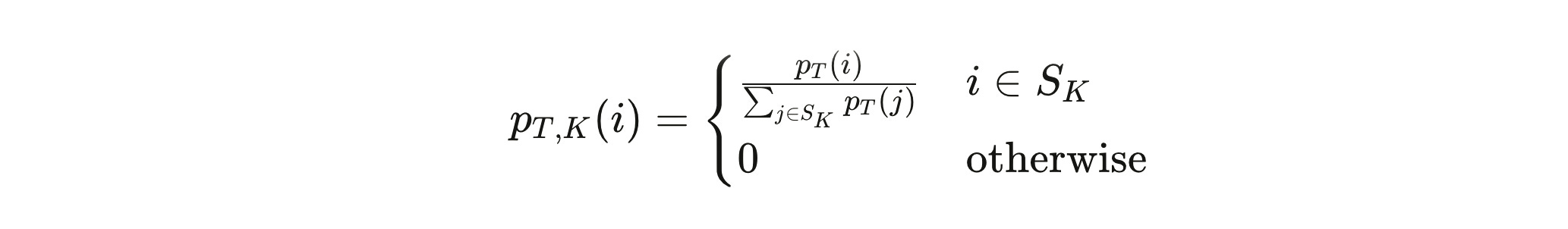
Top-P (nucleus sampling) takes a more adaptive approach. Instead of a fixed count, it asks: what is the smallest set of tokens whose cumulative probability meets some threshold pp p? Sort tokens by probability, add them up until you hit the threshold, keep that set. When the model is confident—distribution is already spiked—the nucleus is small. When the model is uncertain—distribution is flat—the nucleus grows. The method adapts to the model’s own uncertainty in real time.
The practical difference matters. Top-K with K=3K = 3 K=3 on a highly confident model and a highly uncertain model gives you very different experiences. Top-P with p=0.9p = 0.9 p=0.9 automatically adjusts: tight when the model knows, loose when it doesn’t.
Most production systems combine all three: temperature shapes the distribution, then a truncation rule prunes it, then you sample from what’s left. The output you receive is a single draw from that shaped, pruned distribution.
Now here is where this stops being a theoretical exercise and starts being a design problem.
Researchers studying exemplar selection for few-shot learning discovered that choosing which examples to include in a prompt is itself a stochastic optimization problem. Because the model’s response to any given set of examples is a probabilistic event, finding the “best” prompt isn’t a search through a fixed landscape—it’s an optimization problem under uncertainty.
The CASE framework—Challenger Arm Sampling for Exemplar selection—treats this as a multi-arm bandit. Each possible subset of examples is an “arm.” Pulling the arm means calling the model with that prompt and observing the reward: did the model get the answer right? The challenge is finding the best arms from an exponentially large space while minimizing the number of expensive model calls.
The results are stark. CASE reduces the number of required model calls by 87% compared to state-of-the-art methods. It runs up to 7x faster. It improves task accuracy by up to 15.19%. The mechanism is principled: a gap-index-based exploration strategy that maintains a “challenger set” of next-best candidates, iteratively evaluated against current leaders. The stochasticity of the machine is not fought—it’s incorporated into the optimization itself.
The deeper lesson: the same probabilistic nature that makes outputs variable is what makes systematic optimization possible. You can’t do a bandit optimization on a deterministic lookup table.
There is a limit to how far sampling parameters can push a model, and the math of Expert Default Bias reveals exactly where that limit sits.
Consider a simple experiment: prompt GPT-4o to simulate students of different proficiency levels solving a straightforward arithmetic problem. A student who earns A grades. A student who earns D grades. Ask both to calculate the earnings for 50 minutes of babysitting at $12 per hour.
The A-student response is clean: 50/60=5/650/60 = 5/6 50/60=5/6; 5/6×12=$10.005/6 \times 12 = $10.00 5/6×12=$10.00. The D-student response hedges: *”Maybe like $10? I think she earned $10.”* Different tone, different confidence markers—but the same answer. The underlying calculation never changes. Not for the B-student, not for the C-student, not for the D-student.
This is not a failure of prompt engineering. It is a feature of the distribution. The probability mass for the correct answer to a simple arithmetic problem is so dominant in a well-trained model that no temperature setting, no persona prompt, no amount of stylistic instruction can shift the sampling process toward a realistic arithmetic error. The logit gap for the correct token is enormous. The tail—where the wrong answers live—is so suppressed it might as well not exist.
What you can change with sampling parameters is the presentation of competence. What you cannot change, without specialized fine-tuning, is the underlying logical execution.
Suppose the stochastic nature of the machine isn’t a design flaw to be suppressed. Suppose it’s a control surface.
This is the core insight of agentic AI: treat sampling parameters as variables in a feedback loop, not fixed settings on a dial.
An agentic system generates a draft under some initial settings. It evaluates that draft—using confidence scoring, constraint checking, factuality heuristics. Based on what it finds, it adjusts the settings and generates again.
The confidence signal can come directly from the logits. Define the gap at each generation step:
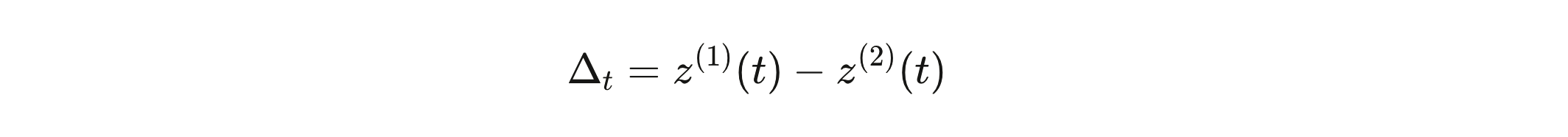
Average these gaps across the full generation. A low average means the model was frequently uncertain—the distribution was often nearly flat, the draws were often close calls. A high average means it was decisive throughout.
The adaptive policy follows naturally. High confidence → modest temperature, allow Top-P for fluency. Low confidence → lower temperature to reduce randomness, or switch to a verify-then-write mode. Creative task → raise temperature in designated sections, keep it low in factual sections.
given prompt c
settings := (T=0.7, top_p=0.9)
draft := generate(c, settings)
score := evaluate(draft) # constraints, hallucination heuristics, etc.
if score.low_confidence:
settings.T := max(0.2, settings.T - 0.3)
settings.top_p := min(0.9, settings.top_p)
draft2 := generate(c, settings)
if score.too_boring and task_is_creative:
settings.T := settings.T + 0.3
settings.top_p := settings.top_p + 0.05
draft3 := generate(c, settings)
return best(draft, draft2, draft3)The agent isn’t adding new knowledge. It’s steering sampling based on feedback. The difference between a model and an agent isn’t intelligence—it’s the feedback loop.
This approach has measurable payoffs. Systems using self-consistency decoding—generating multiple diverse reasoning paths and selecting by majority vote—show +17.7% accuracy gains on tool-based factual datasets. The stochasticity is not eliminated. It’s harnessed for exploration, then collapsed via aggregation into a reliable answer.
The Wonder Woman experiment comes full circle here.
At T=0T = 0 T=0, the model is not thinking. It is convergingon the most probable continuation of its training data. The answer is reliable but brittle—a single path through a probability landscape that was shaped to produce exactly this output.
At T=1.2T = 1.2 T=1.2, the model is not hallucinating randomly. It is sampling from regions of the distribution that exist, that were shaped by real training data, but that are rarely the right answer to this question. *Bizarro Wonder Woman* is in there because the model has read about Bizarro Wonder Woman. The problem isn’t invention—it’s sampling too far into the legitimate but irrelevant.
The design insight: you are not configuring an intelligence. You are reshaping a distribution. The intelligence—such as it is—emerges from the shape of what was learned. Your job, as a user or a system builder, is to choose the right sampling regime for the task at hand.
For auditable facts: low temperature, tight truncation, verify outputs. For brainstorming: moderate temperature, wide nucleus, expect variance. For creative synthesis: high temperature in the creative sections, low temperature in the factual anchors, aggregate across multiple draws.
The model is a stochastic machine. It has always been a stochastic machine. The only question is whether you are steering it or just hoping.
LLM Exercises
Exercise 1 — Temperature Variance Lab
Choose a prompt with both a factual component (a specific number, date, or name) and a stylistic component (a tone, a metaphor, a voice). Run N=20N = 20 N=20 generations at T∈{0,0.7,1.2}T \in \{0, 0.7, 1.2\} T∈{0,0.7,1.2} with identical truncation settings.
Compute the unique completion rate:
U=# unique outputsNU = \frac{\text{\# unique outputs}}{N}U=N# unique outputs
Also compute the average pairwise Levenshtein distance across completions at each temperature. Plot UU U and mean distance as functions of TT T.
*Prompt to Claude:* “I’m running this experiment and have my completion data as a list of strings. Write Python code that computes UU U and the average pairwise Levenshtein distance for a list of NN N text completions. Then help me interpret the results—what does a UU U close to 1.0 mean for system reliability versus a UU U close to 1/N1/N 1/N?”
Exercise 2 — Top-K vs. Top-P Failure Mode Mapping
Hold temperature fixed at T=0.7T = 0.7 T=0.7. Vary K∈{3,20,200}K \in \{3, 20, 200\} K∈{3,20,200} and p∈{0.5,0.9,0.99}p \in \{0.5, 0.9, 0.99\} p∈{0.5,0.9,0.99} across the same creative writing prompt.
Your goal is to map the failure modes, not just the outputs. For each setting, identify whether the failure (if any) is: (a) repetition and brittleness, (b) incoherence and drift, or (c) neither.
Prompt to Claude: “Here are six completions from a creative writing prompt under different Top-K and Top-P settings. For each one, tell me: is this failure mode (a) repetitive/brittle, (b) incoherent/drifting, or (c) neither? Then explain what the sampling setting was likely doing mathematically to produce that outcome.”
Exercise 3 — Expert Default Bias Investigation
Replicate the proficiency role-play experiment. Prompt a capable LLM (GPT-4o, Claude, or equivalent) to simulate four students—A, B, C, and D proficiency—solving the same arithmetic problem. Record not just the final answer but the intermediate steps.
Now try a harder problem—one where a realistic intermediate error is possible (e.g., a multi-step percentage calculation). Does the Expert Default Bias hold? At what point does the model begin to generate plausible errors?
Prompt to Claude: “I’ve run the proficiency role-play experiment and collected outputs. Help me analyze whether the model’s logical execution actually changed between proficiency levels, or only the surface presentation. What statistical test would distinguish genuine logical variation from stylistic variation?”
Exercise 4 — Design an Agentic Sampling Policy
Define a two-phase generation task: (a) produce a structured outline for a technical explanation, (b) write the final explanation for a non-expert audience.
For each phase, specify: temperature, truncation method (Top-K or Top-P), number of samples to generate, and any evaluation criterion used to select among samples.
Justify each choice in terms of the confidence signal Δt\Delta_t Δt and the entropy H(pT)H(p_T) H(pT) you would expect in each phase.
Prompt to Claude: “Review my agentic sampling policy specification. For each phase, tell me: (1) whether my temperature choice is appropriate given the expected entropy of the task, (2) whether Top-K or Top-P is better suited and why, and (3) what evaluation criterion you would use to select the best output from multiple samples.”
Exercise 5 — CASE Bandit Framing
You are building a few-shot prompt for a classification task. You have 20 candidate examples and need to choose 5. Brute-force search requires testing (205)=15,504\binom{20}{5} = 15{,}504 (520)=15,504 combinations.
Frame this as a multi-arm bandit problem. Define: what is the “arm,” what is the “reward,” what is the exploration-exploitation tradeoff, and how would you implement a simple ϵ\epsilon ϵ-greedy strategy to reduce the number of required LLM calls?
*Prompt to Claude:* “I’ve framed my exemplar selection problem as a multi-arm bandit with arms defined as [your definition]. Help me implement a basic ϵ\epsilon ϵ-greedy search that: (1) starts with random sampling of arm subsets, (2) exploits the current best arm with probability 1−ϵ1 - \epsilon 1−ϵ, and (3) tracks running accuracy estimates. Then explain where the CASE framework’s gap-index strategy improves on this naive approach.”
Exercise 6 — Wonder Woman Stochastic Audit
Use the Wonder Woman/Boeing 737 prompt as a benchmark. Run it 10 times at T=0T = 0 T=0 and 10 times at T=1.0T = 1.0 T=1.0.
For each output, classify every factual claim as: (a) correct and consistent, (b) correct but phrased differently, (c) correct but with irrelevant additions, or (d) factually drifted.
Compute the drift rate D=(d) outputs/ND = \text{(d) outputs} / N D=(d) outputs/N at each temperature.
Prompt to Claude: “Here are my 20 Wonder Woman/Boeing completions with their temperature settings. Classify each factual claim using the four-category scheme and compute the drift rate at each temperature. Then explain: at what point in the probability distribution does ‘irrelevant but accurate’ (category c) transition to ‘factually drifted’ (category d)? What does this tell us about where the model’s knowledge of these two facts actually lives in its weights?”
