
The Email That Only You Could Write
Joyce Ho's inbox is a data problem. The students who understand that are the ones who get a response.

The reading is not the obstacle between you and the email. The reading is the email.
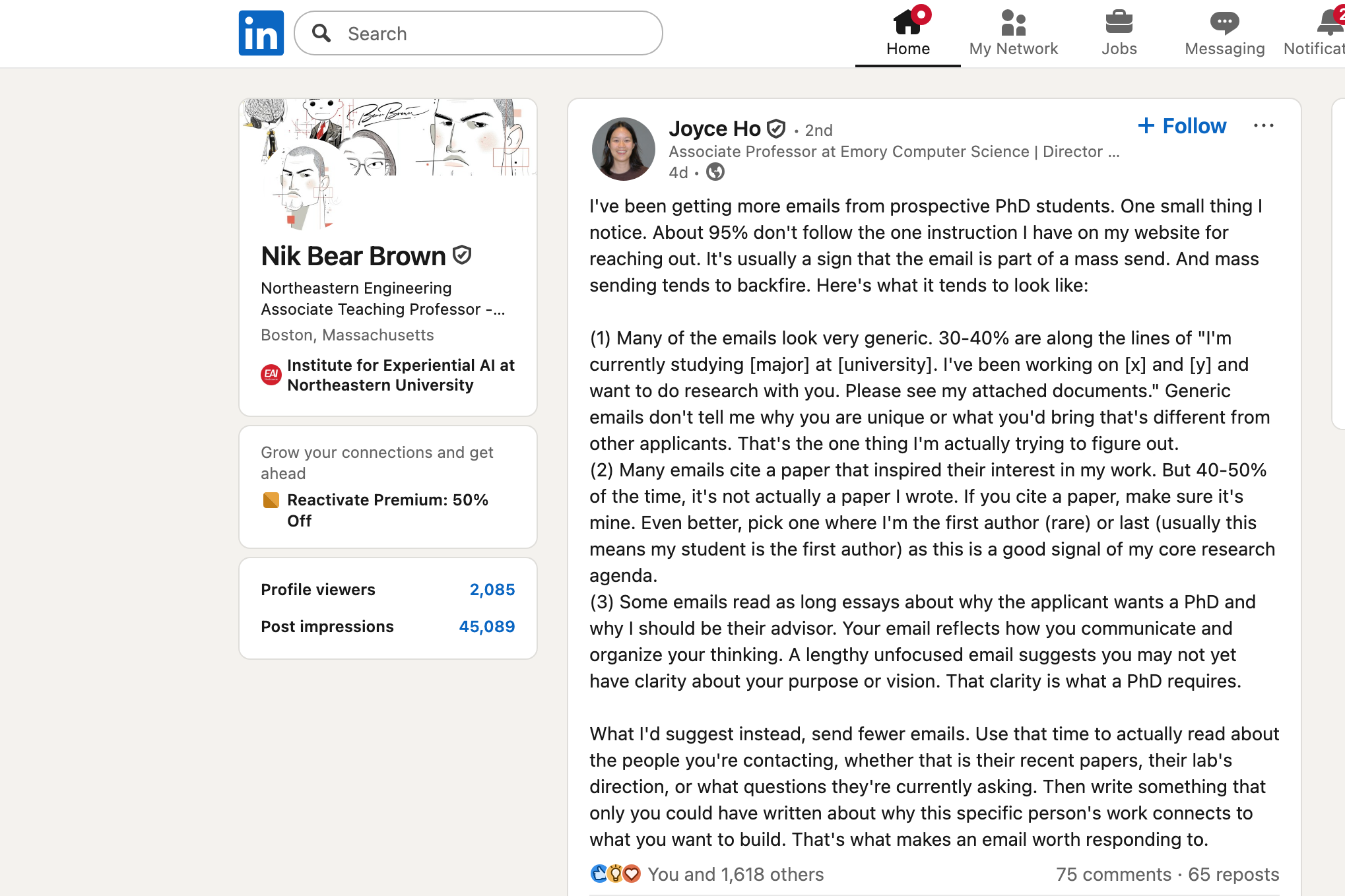
That sentence belongs at the front of what follows, because it is the argument — and because the PhD applicants who most need to hear it are the ones most likely to stop reading before they reach a closing line. Joyce Ho, Associate Professor of Computer Science at Emory University, posted recently about the emails she receives from prospective students. She wrote with the precision of someone for whom frustration has resolved into empirical clarity. The data is not complicated: approximately 95% of the emails she receives fail to follow a single instruction she has placed, explicitly, on her website.
Not a complicated instruction. A subject line.
What 95% Failure Looks Like
The email is optimized for sending volume, not for reception. That is the diagnosis in one sentence, and it explains everything about the three failure modes Ho identifies.
The first is the generic introduction: I am currently studying X at Y university. I have been working on A and B and want to do research with you. These emails, 30 to 40% of her inbox, contain almost no information about the candidate’s specific contribution. They describe the applicant’s general existence in the vicinity of computer science. What a faculty member forming a research partnership actually needs to know — what specific problem animates you, what you have already tried, what gap in the literature keeps you awake — is absent. The sender and the receiver both know it is a form.
The second failure is the misattributed citation. In 40 to 50% of the emails that do cite a paper, the paper is not one Ho wrote. The citation is supposed to say: I have been in conversation with your research. I have a position on it. When the paper belongs to someone else — or to no one traceable — the signal inverts. It says: I searched for papers near your name. I found something adjacent. I moved on.
The third failure is the essay. Long, unfocused, comprehensive letters about why the applicant wants a PhD, why they deserve a mentor, why their life trajectory has prepared them for this moment. Ho’s observation here is precise: an email reflects how you communicate and organize your thinking.
A PhD requires exactly this capacity — the selection of the important from the merely present, the compression of months of thinking into a question that is worth asking. An email that cannot do this on a single page is not evidence of depth. It is evidence of its absence.
The Signal in the Noise
Ho’s field provides the vocabulary for understanding what she is actually measuring.
In healthcare data mining, the central challenge is separating signal from noise in datasets that are dense, heterogeneous, and incomplete. Electronic health records are not designed for research. They are designed for billing and clinical documentation. The patient encounter generates thousands of data points — ICD codes, medication orders, lab values, nursing notes — and the researcher’s task is to identify which patterns reveal genuine clinical structure and which are artifacts of the documentation system itself.
Nonnegative tensor factorization, which is the mathematical core of Ho’s phenotyping work, addresses this problem by decomposing multi-dimensional patient data into latent factors. You start with a tensor — a three-dimensional array where one axis is patients, one is diagnoses, one is time — and you factor it into components that represent coherent clinical groupings. The method is a search for structure that is genuinely there, as distinguished from structure that is an artifact of how the data was collected.
The email problem is structurally identical. A faculty member’s inbox is a tensor of sorts — hundreds of messages across many axes of applicant background, research interest, and communication quality. The genuine signal is the candidate whose specific technical experience maps onto an open problem in the lab. The noise is everything else.
The “More Data More Fun” subject line is a filter. It does not identify the best candidate. It excludes, efficiently, the candidates who did not read the data. This is not an arbitrary gatekeeping mechanism. It is a reasonable inference from available evidence. If you cannot locate and follow one instruction on a webpage, what does that predict about your behavior in an environment where the documentation is incomplete, the data is messy, and the consequences of careless execution affect clinical decision-making?
Reading the Author, Not Just the Paper
Read about the questions they’re currently asking. Not the papers — the questions. The papers are the best evidence for the questions, but they are not the questions themselves.
In computer science and biomedicine, where an author list can run to a dozen names, position is meaning. The first author is typically the person who did the work — who ran the experiments, wrote the code, drafted the manuscript. The last author is typically the principal investigator: the person who secured the funding, framed the question, supervised the team, and bears ultimate intellectual responsibility for the contribution.
When Ho says to cite a paper where she is first or last author, she is pointing toward papers that represent her own thinking, her own research agenda, her own intellectual commitments — not papers where she contributed a dataset or reviewed a draft from the margins. The distinction matters because a PhD is an apprenticeship in thinking. A student who wants to work with Ho needs to understand what Ho is actually working on, not what someone in an adjacent lab happened to cite her on.
Her early first-author work — phenotyping algorithms from the mid-2010s — represents the mathematical foundations of the lab’s approach to EHR analysis. Her recent last-author work — on large language models for biomedical concept linking, on heterogeneous graph embeddings for clinical prediction — represents where the lab’s thinking has arrived after a decade of applied research. Both are legitimate points of entry. Neither is meaningful if the paper was identified by keyword search rather than by reading.
A student who can articulate the lab’s current questions — imperfectly, provisionally, but genuinely — has demonstrated something that cannot be faked by any template.
What an Email That Only You Could Write Looks Like
Ho’s formulation is worth stating again plainly: write something that only you could have written about why this specific person’s work connects to what you want to build.
This requires, first, that you have something specific you want to build. Not a general desire to do research, not a credential-seeking impulse dressed in the language of curiosity, but a problem that has been bothering you long enough and specifically enough that you have developed a tentative position on it. It requires, second, that you have read the faculty member’s recent work with sufficient attention to understand where their questions and your questions might intersect. It requires, third, that you have the discipline to express this intersection concisely — without padding, without the performative autobiography.
The PhD email is a proof of concept. It is asking a professor to bet a significant portion of their finite mentoring capacity on the proposition that you are worth the investment. The proof it needs to provide is not that you are generally intelligent or broadly motivated. It is that you have already done the work of understanding where your specific intellectual interests connect to theirs, and that you are capable of the clarity and precision that collaborative research requires.
Ho runs a lab called the Practical Data Mining & Exploration Lab. The word “practical” is not incidental. The projects are funded, clinically grounded, and oriented toward problems that affect real patients. The students who come out of this lab go to Oak Ridge, Harvard, Microsoft Research, Amazon. This is not a lab where the questions are abstract or the standards are loose.
The email that gets read is the email that knows this. It says, in effect: I have been in your lab’s archive. I understand what you are building. Here is what I can contribute that no one else can. If writing that email means sending twenty instead of a hundred, the conversion rate will vindicate the math. It was always in favor of the careful.
The subject line reads “More Data More Fun.” Finding it requires reading the page. Following it takes thirty seconds. Together they take perhaps ten minutes of actual attention.
The reading is not the obstacle between you and the email. The reading is the email.
Forward this to a student in your department who is in the outreach phase — it’s exactly the kind of thing faculty share with advisees. And if you’re a faculty member with your own version of this inbox problem, I’d like to hear how you’ve handled it in the comments.
Nik Bear Brown is an Associate Teaching Professor of Computer Science and AI at Northeastern University and founder of Humanitarians AI (501(c)(3)). Subscribe at nikbearbrown.substack.com
Tags: PhD applications · academic career · cold email · graduate school · research careers