
The Intelligence We Missed While Climbing the Ladder
On Association, Causation, Simulation, Judgment—and Why They're Parallel Competencies, Not Rungs

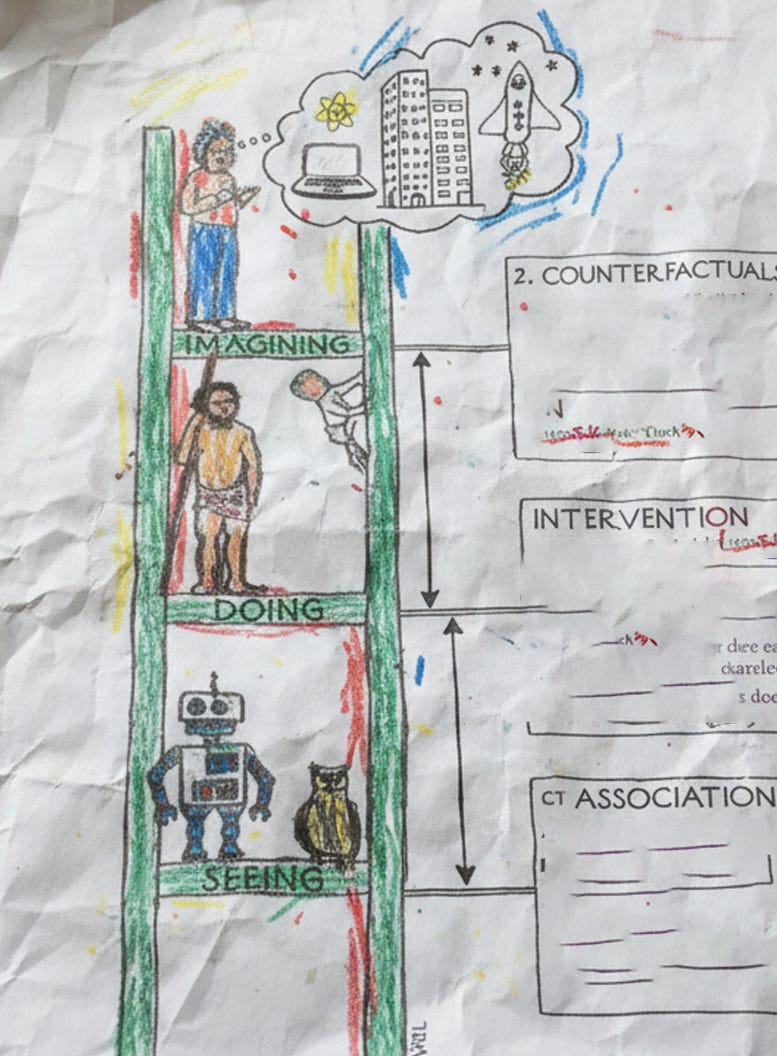
You open a conversation with an AI system and ask it to reason about a firing squad. A court issues an order. A captain signals two soldiers. Either bullet kills the prisoner. You pose the counterfactual: what if Soldier A had refused to shoot? The AI answers correctly: the prisoner would still be dead. Soldier B’s bullet would have done the work.
Judea Pearl, the computer scientist who won the Turing Award for his work on causality, built the framework that explains why this question matters. His “Ladder of Causation”—published in The Book of Why and taught in statistics departments worldwide—distinguishes between three types of reasoning. Association (seeing): observing that A fired tells us B probably fired too. Intervention (doing): predicting what happens if we make A fire. Counterfactuals (imagining): reasoning about what would have happened in an alternative world where A refused.
The ladder gives us the cleanest vocabulary we have for these distinctions. It formalizes the difference between correlation and causation, between watching and acting, between history and alternative possibility. Pearl’s do-calculus works exactly as advertised for the problems it was designed to solve: identifying which causal questions can be answered from observational data, designing interventions that produce reliable effects, reasoning rigorously about blame and responsibility.
But LLMs—large language models built entirely on statistical associations between words—complicate what we thought that vocabulary implied about intelligence. These systems don’t store causal diagrams. They don’t perform do-calculus. They predict the next token based on patterns in their training data. Yet they answer counterfactual questions thousands of times per second, often correctly, sometimes brilliantly, occasionally in ways that reveal something we missed.
The ladder is a brilliant taxonomy of causal queries. What deserves debate is whether it’s also a taxonomy of intelligence—or whether intelligence is better described as parallel competencies coordinated by judgment, with causation as one mode among several, not the apex of a hierarchy.
The Atoms and What They Actually Rule Out
Pearl’s argument against “cheating” rests on elegant combinatorics. Consider ten binary variables—things that can be either true or false, on or off, alive or dead. You could pose roughly 30 million queries about relationships between these variables: What’s the probability the outcome is one, given we observe X equals one and make Y equal zero and set Z to one? With more variables, or more possible states for each, the numbers explode beyond comprehension. Pearl’s conclusion: “Searle’s list would need more entries than the number of atoms in the universe.”
This demolishes John Searle’s Chinese Room thought experiment, which suggested a machine could pass the Turing Test by looking up pre-written answers without understanding anything. Pearl is unequivocally right: a literal lookup table can’t scale. You cannot store all possible question-answer pairs. The computational physics makes it impossible.
But what exactly does this impossibility prove? The step that deserves more scrutiny is what counts as a “compact representation.” Pearl demonstrates that explicit causal graphs—nodes and arrows encoding who influences whom—provide one such representation. From a handful of structural assumptions, you can derive answers to combinatorially many queries. The math is undeniable.
What the atoms argument doesn’t rule out: compression algorithms, learned function approximators, latent representations that encode structure without storing it explicitly, or any other form of generalization that achieves compact storage through means other than explicit causal diagrams.
The human brain, after all, operates under the same atomic constraints Pearl describes. We have perhaps 100 billion neurons and 100 trillion synapses—a vast number, but effectively zero compared to the state space of even modest causal systems. If we’re not storing lookup tables, and we’re not consciously manipulating formal causal graphs for every judgment we make, then we must be doing something else. Something that achieves compression through different computational means.
What the Machines Revealed—and What They Didn’t
When OpenAI released GPT-3 in 2020, researchers rushed to test it on causal reasoning tasks. The results defied clean categorization. Sometimes impressive, often wrong, always opaque. But what emerged from thousands of tests wasn’t a confirmation of the ladder as an intelligence hierarchy. It was evidence that the ladder’s rungs don’t map cleanly onto computational architectures or cognitive capabilities.
Tasks researchers had classified as “interventional” (Rung 2) or “counterfactual” (Rung 3)—supposedly requiring formal causal machinery—turned out to be sometimes solvable through pattern matching. Not always. Not perfectly. Not reliably under distribution shift. But far more often than the theory predicted. The models weren’t learning to build causal diagrams. They were learning that in text written by humans, certain linguistic patterns predict certain outcomes. When someone writes “if A hadn’t shot,” they’re usually about to describe an alternative sequence of events. The model completes the pattern.
This revelation cuts multiple ways. It exposes how much of what we called “causal understanding” might be sophisticated pattern recognition operating on data where humans have already encoded causal structure. But it doesn’t mean formal causal reasoning is obsolete or that associations can solve every problem. What it does mean requires careful statement.
Pearl defenders would correctly note: LLMs aren’t doing genuine interventions. They’re not manipulating real mechanisms. They’re echoing training data that contains humans’ descriptions of interventions. When you test an LLM on truly novel mechanism changes—causal structures it has never encountered in any form—performance degrades. Association-based systems struggle with transportability: moving knowledge from one causal regime to another.
This is where Pearl’s framework matters most. Explicit causal models enable something critical: reasoning under genuine mechanism change, predicting effects of interventions never seen before, maintaining coherence when the rules of the world shift. Identifiability theory tells you what you can learn from data. Transportability tells you what transfers across contexts. These aren’t just mathematical niceties—they’re survival requirements for medicine, policy, and engineering.
But here’s what LLMs do demonstrate: causal-looking outputs can arise from association when the training distribution is sufficiently rich and humans have already done the causal work of structuring language. That means the ladder cannot function as a simple intelligence hierarchy, a developmental sequence where you must master Rung 1 before accessing Rung 2, or where Rung 3 represents “more advanced” thinking than Rung 1.
The relationship isn’t hierarchical. It’s regime-dependent. Different computational approaches excel in different territories.
The Judgment That Shapes Every Model
Return to Pearl’s firing squad, presented in The Book of Why as demonstration of formal causal reasoning. You have five variables: Court Order, Captain, Soldier A, Soldier B, Death. Draw the arrows: Court Order → Captain → Soldiers → Death. Apply the do-operator. Answer the counterfactual. Pure logic, cleanly executed.
But trace backward to where that diagram originated. Someone chose those five variables from the infinite possible ways to describe an execution. Why not include the captain’s confidence level? The wind conditions? The soldiers’ aim accuracy that day? Each choice reflects a judgment: this matters, that doesn’t.
Someone decided the causal structure. But alternative structures are mathematically possible. Maybe political pressure influences both the court and the captain. Maybe the soldiers intimidate the captain. Maybe there’s a feedback loop between military and legal authority. Each structure could be consistent with observational data. Choosing among them requires judgment about mechanisms, not pure logic.
Someone chose the level of abstraction: “Court Order” as a single variable rather than decomposing it into judge’s decision, clerk’s paperwork, document transmission, captain’s receipt. Someone judged these details irrelevant to the question being asked.
And someone chose the functional form: deterministic cause and effect, when reality operates probabilistically. The captain signals, and Soldier A fires... with what probability? Under what conditions might A hesitate or miss? Pearl abstracts these questions away, judging them “close enough to deterministic” for the point being illustrated.
None of this diminishes the value of the formalism. Making assumptions explicit is an advantage. You can debate them, test them, revise them. That’s exactly why causal diagrams are powerful—they force you to declare where your judgment has made commitments. But the formalism doesn’t eliminate judgment. It formalizes where the judgment hides.
The same holds—less transparently—for association. When an LLM generates an answer, it’s not pulling from a lookup table. It’s navigating a high-dimensional space of linguistic and conceptual patterns, weighted by frequency, context, and structural cues. Those weights encode the collective judgments of millions of humans about what matters, what causes what, what to mention and how to describe sequences of events. Association isn’t judgment-free “cheating.” It’s compressed, collective judgment, rendered opaque by the architecture.
Both approaches require judgment. The difference is accountability. Causal diagrams make assumptions inspectable. Associations bury them in billions of parameters. But making assumptions explicit doesn’t make them correct. A clearly-stated wrong model is still wrong.
The Intelligence of Smoke and Probability
Consider smoking and cancer. Pearl’s framework handles this elegantly: P(cancer∣do(smoke))>P(cancer∣do(not smoke))P(\text{cancer}|\text{do}(\text{smoke})) > P(\text{cancer}|\text{do}(\text{not smoke})) P(cancer∣do(smoke))>P(cancer∣do(not smoke)). Smoking doesn’t guarantee cancer. It increases probability. The arrow from S to C represents a causal relationship, not a deterministic guarantee. The unobserved variable U—genetics, environmental exposures, immune function, luck—points at cancer alongside smoking, creating variance in outcomes.
This is exactly the kind of rigorous thinking medicine needs. The formalism prevents confusion between seeing correlations and predicting intervention effects. It separates questions about individual outcomes from questions about population-level causation. It makes clear what you can learn from observational data versus what requires experiments.
Yet people regularly reject this causal claim by pointing to their grandfather who smoked two packs a day and lived to ninety. This isn’t pure ignorance. It reflects a different form of intelligence: recognizing that causal models are always lossy compressions of vastly more complex systems. The model captures the largest signal—smoking matters—while abstracting away most of the mechanism. The grandfather isn’t a refutation of the causal model. He’s a data point in the error term. But to the person making the argument, the grandfather is proof that the story is incomplete.
And they’re right. The story is incomplete. All models are. The question is whether that incompleteness matters for the decision at hand.
This creates an asymmetry. It’s easy to generate a plausible causal explanation. It’s hard to verify that explanation holds under intervention. It’s easy to point to an exception. It’s hard to communicate what “probabilistic causation” means to someone thinking in terms of deterministic rules.
Narrative intelligence—the ability to tell stories that make sense of messy reality—serves genuine cognitive functions: compression, sensemaking under uncertainty, social coordination, hypothesis generation. That’s not fake intelligence. It’s survival-grade cognition optimized for speed and meaning rather than correctness under mechanism change. The danger comes when narrative imagination pretends to be causal proof, when someone weaponizes the exception to deny the pattern. This is the structure of climate denial, vaccine hesitancy, and financial fraud: taking probabilistic relationships and demanding they work as deterministic guarantees, then declaring the entire framework invalid when they don’t.
Pearl’s work helps diagnose this confusion. The ladder makes explicit what type of claim is being made. But recognizing that someone is answering a Rung 1 question when a Rung 2 question was asked doesn’t tell you which form of reasoning is “more intelligent.” It tells you which form fits the problem structure.
Parallel Competencies, Not Developmental Stages
What LLMs force us to see is that intelligence operates in parallel modes, not a single hierarchy. The ladder is a map of question types. The mistake is treating it as a developmental sequence of minds.
Association: Pattern completion, interpolation, default reasoning, semantic abstraction. Fast, robust to noise, requires massive data, opaque in operation. Excels within the training distribution. Struggles with genuine novelty and mechanism shifts.
Formal causation: Intervention prediction, counterfactual reasoning, mechanism specification. Provable, transportable across regimes, requires explicit structure. Brittle when the model misspecifies reality. Computationally expensive.
Simulation: Mental models, analogical reasoning, forward projection. Intuitive, flexible, context-sensitive. Accessible to human cognition without formal training. Fails under complexity and when intuitions systematically mislead.
Heuristics: Rules of thumb, compressed decision procedures, fast judgments. Efficient, domain-specific, often surprisingly accurate within their validity range. Catastrophically wrong outside it.
Each mode has different computational costs, different failure modes, different domains where it shines. The question isn’t which represents “real intelligence.” The question is: which mode fits this problem, how much verification is required, and what’s the cost of being wrong?
This is where judgment enters—not as another rung on the ladder, but as the meta-intelligence that coordinates across modes. Judgment asks: Is this a prediction problem within a familiar regime, where fast association suffices? Or an intervention problem where I need explicit mechanism tracking? Or a high-stakes decision requiring multiple modes cross-checked against each other?
Judgment detects distribution shift, novelty, adversarial framing, misspecified abstractions. It recognizes when “good enough” is actually good enough and when formal proof is necessary. It weighs the cost of being wrong against the cost of verification. It decides whether to trust a confident-sounding answer or demand to see the mechanism.
Current LLMs can simulate all the reasoning modes in text. They can complete patterns associatively, manipulate logical symbols, roleplay scenarios, encode heuristics. What they can’t reliably do is judge when they’re out of their depth, escalate to stricter verification when needed, or weight consequences they don’t experience. They generate answers at equal confidence regardless of reliability.
That’s the real question: not “can LLMs do causal reasoning?” but “can they judge when causal reasoning is necessary versus when association suffices?”
Opening the Debate
Pearl’s Mini-Turing Test was designed to separate true understanding from statistical mimicry. Give a machine a causal scenario—the firing squad, for instance—and test whether it can answer associational questions (if A fired, what does that tell us about B?), interventional questions (what if we make A fire?), and counterfactual questions (if A hadn’t fired, would the prisoner live?). Only a system with genuine causal knowledge should pass all three, Pearl argued.
But the test contains an ambiguity that matters. If a machine answers correctly, does that prove it has a causal model? Or does it reveal that the test itself operates within a regime where sophisticated pattern matching can succeed—because humans describing the world in text have already encoded causal structure in linguistic patterns?
The ambiguity doesn’t invalidate the test. It sharpens what the test actually measures: not “does this system have intelligence?” but “does this system maintain coherence under interventions and mechanism shifts?” That’s a crucial capability. It’s also not the only form intelligence takes.
Pearl was right that explicit causal models enable something critical: reasoning under genuine novelty, maintaining coherence when causal regimes change, proving what can be learned from data. Association-based systems fail these stress tests. They interpolate brilliantly but don’t reliably extrapolate to different causal structures.
But that’s a statement about robustness under shift, not about what counts as intelligence in the first place. Association is how intelligence runs fast in familiar territory. Formal causal reasoning is how intelligence stays correct when the territory changes. Simulation is how intelligence navigates when data is sparse. Heuristics are how intelligence operates under cognitive constraints. All are real. All are necessary. None supersedes the others.
The ladder metaphor suggests a hierarchy—lower rungs primitive, higher rungs advanced, one superseding the other. What LLMs actually demonstrate is complementarity. Different approaches excel in different regimes, coordinated by judgment about which matters when.
What This Means for How We Think About Thinking
The broader lesson extends beyond AI systems to human reasoning. Most of the time, most people operate primarily on association, simulation, and heuristics—not formal causal analysis. They see correlations and infer causation. They rely on stories and intuitions. They use rules of thumb that work in their domain without proving they work.
This isn’t a failure of intelligence. It’s an allocation of computational resources. Formal causal reasoning is expensive: cognitive effort, time, data requirements, expertise. You deploy it when the stakes justify the cost, when you have enough structure to build a valid model, and when the decision truly requires mechanism-level understanding rather than pattern recognition.
Declaring that only formal reasoning counts as “real intelligence” while dismissing association as mere mimicry is a category error. It’s like claiming only peer-reviewed proofs count as real knowledge while dismissing craft expertise, traditional ecological knowledge, and practical wisdom as superstition.
The human who reasons causally about smoking and cancer isn’t more intelligent than the human who recognizes the pattern through experience and social learning. They’re using different tools, suited to different purposes. The epidemiologist needs causal models to design interventions and handle confounding. The individual making a health decision might rely on heuristics, social norms, and personal risk assessment. Both are thinking. Both can be appropriate to context.
The danger isn’t in which tool you use. It’s in mismatches: treating association as if it were causal proof, demanding causal proof where association would suffice, building formal models while forgetting they rest on layers of judgment and assumption, or using any single mode when the problem demands coordination across several.
LLMs make these trade-offs visible because they excel at one form of intelligence—compressive pattern completion—while being unreliable at another—coherent reasoning under mechanism change. That doesn’t make them “not intelligent.” It makes them differently intelligent, with a specific reliability profile. We can measure that profile, understand where it breaks, and design systems that compensate for weaknesses.
The same applies to humans. We’re brilliant at some forms of reasoning, terrible at others. We think we’re doing formal causal analysis when often we’re telling stories. We trust intuitions in domains where they systematically mislead. We demand mathematical proof for claims that threaten our identity while accepting flimsy reasoning for claims we want to believe.
The Map We Actually Need
Pearl’s Ladder of Causation represents one of the most important intellectual achievements in statistics and machine learning over the past thirty years. It gives us mathematical tools to answer questions that matter: Does this drug work? Would this policy help? Who is responsible for this outcome? It makes explicit the inferential gap between correlation and causation that informal reasoning often blurs. It enables rigorous reasoning about interventions and counterfactuals in ways that pure prediction cannot match.
None of that changes if we recognize the ladder as a taxonomy of queries rather than a hierarchy of minds. The mathematical framework remains powerful. The insights about identifiability, transportability, and the limits of observational data still hold. What changes is how we think about intelligence—both artificial and human.
Intelligence isn’t a single faculty that develops along one path from primitive to advanced. It’s a collection of parallel capabilities—association, causation, simulation, heuristics, judgment—each optimized for different problems under different constraints. Real competence comes not from climbing higher but from knowing which tool to use, when to trust it, and how to coordinate across modes when complexity demands it.
You might need formal causal reasoning to design a clinical trial or evaluate a policy intervention. Association might be sufficient to recognize a pattern, make a routine decision, or operate efficiently in a familiar domain. Simulation might be the right tool when you lack data but understand mechanisms. Heuristics might outperform complex models in environments where speed matters and the heuristic’s validity range is well-understood. Judgment tells you which is which.
The machines didn’t reveal that association can fake causation. They revealed that both are forms of intelligence, neither reducible to the other, both necessary for functioning in the world. The ladder is a map of question types—a brilliant and useful map. But maps of questions aren’t hierarchies of minds. Opening that debate, making that distinction precise, lets us build better AI systems and think more clearly about our own intelligence.
The territory is more interesting than we thought. The tools we have are more powerful than we realized. And the work ahead—building systems that coordinate multiple forms of reasoning under judgment—is harder and more important than any single ladder can capture.
The point that lands hardest: judgment isn't a rung on the ladder — it's what decides which ladder to climb. That reframe alone is worth the whole read.