
The Ladder of Judgement
Why the Most Important Chart in AI Measures the Wrong Thing

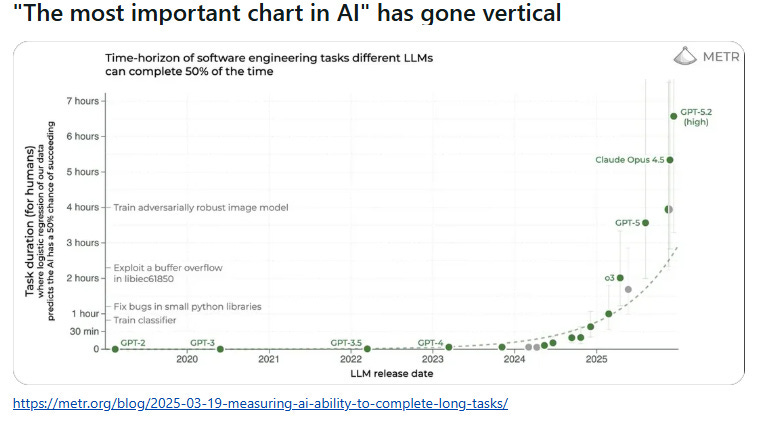
I saw the graph on a Tuesday morning, already viral across Substack and X/Twitter. A clean line, ascending vertically, showing how quickly AI could now complete software engineering tasks. “The most important chart in AI has gone vertical,” the caption declared. The responses are mixed but seem polarized into two camps: technologists celebrating the exponential progress, and junior engineers updating their résumés in quiet panic.
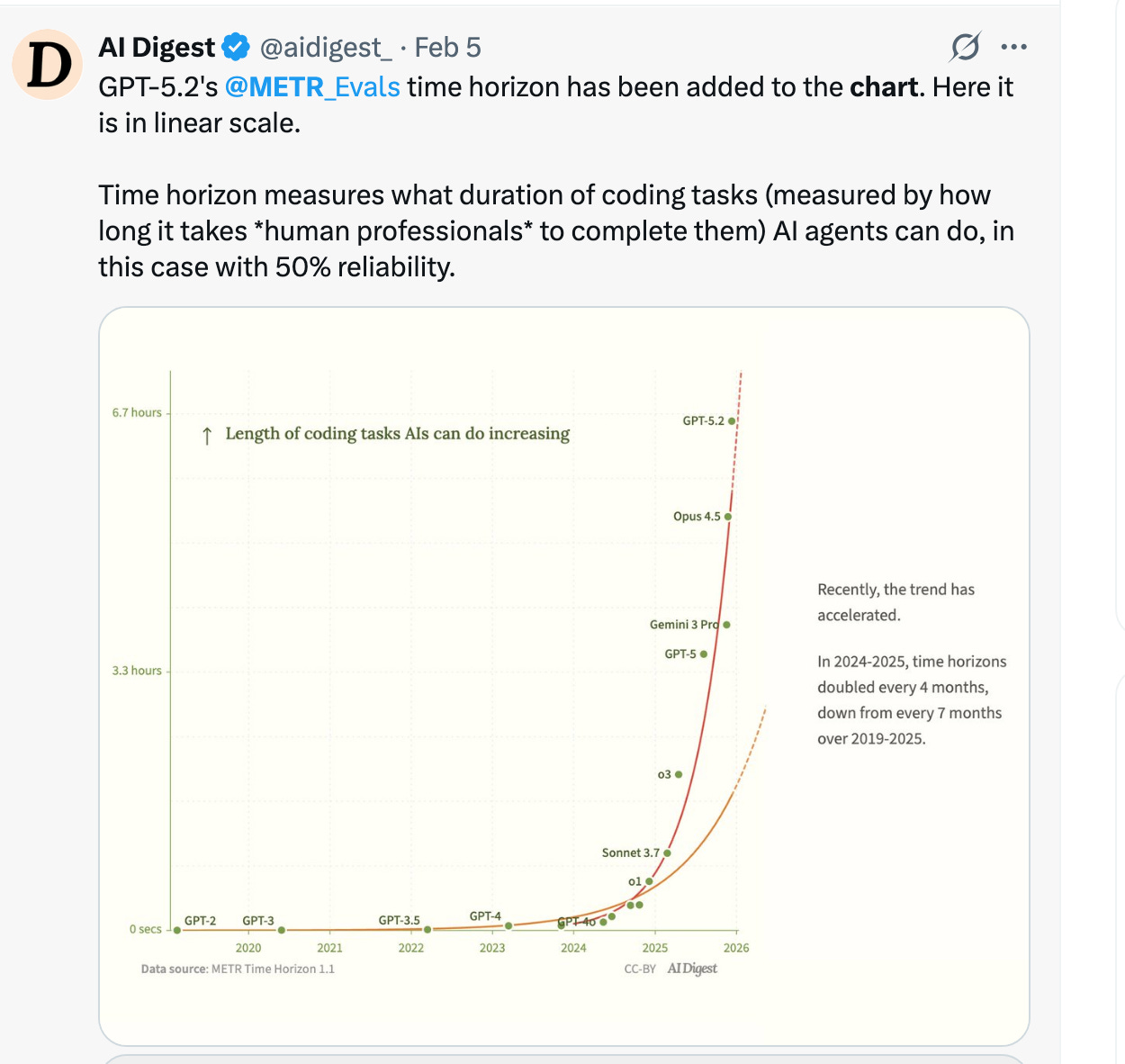
Both camps were reading the chart wrong.
The METR (Model Evaluation & Threat Research) chart tracks “time-horizon to complete 50% of tasks”—showing AI models compressing what once took humans 7 hours into mere minutes. GPT-2 in 2020 could barely manage simple code snippets. Claude Opus 4.5 in 2026 can architect entire systems. The vertical ascent suggests we’re witnessing the obsolescence of a profession in real time.
But here’s what the chart doesn’t show: the 35% of senior engineer time now spent verifying AI output. The 91% increase in code review time. The 154% increase in pull request size. The 59% deployment error rate from AI-generated code. The 19.4% slowdown experienced developers face in controlled settings when the “almost-right” code requires more cognitive effort to debug than writing from scratch would have taken.
The chart measures generation speed. It doesn’t measure judgment quality. And judgment—the ability to know when AI is confidently wrong, when code that compiles will fail catastrophically in production, when the third architectural option is actually the right one—cannot be automated. Not because the technology isn’t powerful enough, but because accountability requires a human signature.
Someone must own what happens when it fails. That someone is not the AI.
The Crisis Hiding in the Vertical Line
You are sitting in a conference room in March 2026 when your CFO presents a simple calculation. Your team ships code 26% faster with AI assistance. Simple algebra suggests you need 26% fewer engineers. The board nods. The decision takes fifteen minutes. You eliminate three junior positions, bank the savings, and tell shareholders you’re “AI-forward.”
What you’ve actually done is severed the talent pipeline that creates the senior engineers your company will desperately need in 2030.
The data is already screaming. Employment for software engineers aged 22-25 declined 13% relative to other age cohorts in 2024-2025, even as positions for engineers aged 35-49 increased 9%. Entry-level job postings requiring three years of experience or less collapsed from 43% to 28% for software development roles. Tech graduate hiring in the UK fell 46% year-over-year. The unemployment rate for bachelor’s degree holders aged 20-24 climbed from 5.2% to 6.2%—higher than those with only associate degrees.
This isn’t the temporary disruption of a technology transition. This is the systematic dismantling of the apprenticeship system that produces the expertise currently commanding $180,000-$400,000 salaries.
Here’s the mechanism: Traditional junior engineers spent their first three years writing CRUD operations, debugging CSS quirks, implementing basic API integrations—the “10,000 hours” of manual coding that developed pattern recognition for what correct code actually looks like. AI now handles 71.7% of these tasks on standard benchmarks, up from 4.4% in 2023.
Companies observe this capability and make what seems like a rational economic choice:
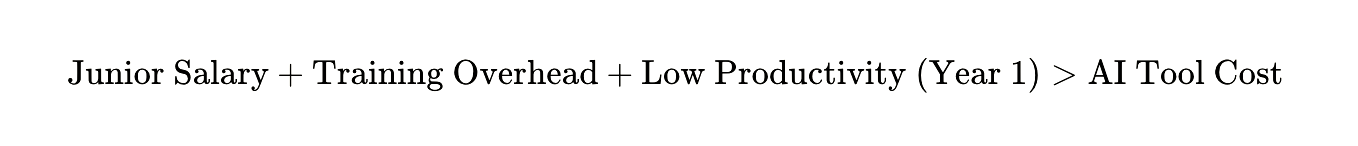
So they eliminate the junior position. Problem solved. Except they’ve confused task completion with expertise development. The 10,000 hours weren’t about producing code—they were about building the intuition to recognize when code that looks right is actually catastrophically wrong.
By 2030, when today’s senior engineers retire or burn out, companies will discover they’ve created what researchers call “Hollow Organizations”: massive AI systems generating code at the bottom, expensive seniors drowning in verification work at the top, and a missing middle layer of mid-level engineers who should have been climbing the ladder for the past five years.
The math is brutal. If junior hiring stays suppressed 20% below 2022 levels through 2026, and normal senior attrition continues at 10% annually, by 2031 the available pool of experienced engineers will have contracted by approximately 70% just as demand remains stable or grows. Companies will bid $600,000, then $800,000, then discover that no salary can purchase expertise that doesn’t exist.
The barrel of 10-year-aged whiskey cannot be created by throwing money at the problem today. You needed to start aging it 10 years ago.
The False Choice
The standard framing presents two options: Cut junior positions for immediate savings, or maintain traditional junior roles that now demonstrate an obvious productivity gap. Both options destroy value.
Option A—the path 94% of companies are currently taking—optimizes the present while mortgaging the future. Option B preserves a training system designed for an obsolete workflow, teaching juniors to manually implement code they’ll never write professionally while AI handles those tasks 10x faster.
There is a third path. But it requires reconceptualizing what “junior engineer” actually means.
The Flight Simulator Insight
Consider how pilots develop judgment. In 1950, a commercial pilot needed 10,000 hours of flight time to encounter the 100 emergency scenarios that build the intuition to land a plane when three engines fail over the Atlantic. They developed expertise slowly, through rare organic encounters with danger.
Modern pilot training uses flight simulators. A trainee can experience 10,000 emergency scenarios in their first 1,000 hours—engine failures, severe weather, hydraulic malfunctions, all compressed into systematic exposure without putting passengers at risk. The result: faster expertise development through wisdom compression.
This is the correct mental model for junior engineers in the AI era.
Traditional path:
Junior writes 100,000 lines of code over 3 years
Encounters ~100 subtle edge cases organically
Develops pattern recognition gradually
Wisdom accrual rate: 0.01 insights/hour
AI-augmented path:
Junior reviews 50-100 AI implementations per week
Sees 10,000+ failure modes systematically in 12 months
Develops pattern recognition through compressed exposure
Wisdom accrual rate: 10 insights/hour
The productivity gain isn’t just 3-5x output. It’s 1000x acceleration in expertise development.
But only if you deliberately design the training program.
The Judgment Ladder: Engineering the Post-Coding Career Path
The solution requires decomposing “senior engineer judgment” into its constituent levels and building a deliberate progression through increasing complexity. Not five years of manual coding, but five rungs of decision-making authority.
Rung 1: The Verification Specialist (Year 0-1)
The role that companies are currently eliminating is actually the most valuable training ground for future architects.
Job title: AI-Augmented Software Verification Specialist
Salary range: $84,000-$100,000
Core responsibility: Ensure AI-generated code meets production standards
What they actually do:
You review 50-100 AI-generated implementations weekly. Not by reading every line—that’s infeasible and unnecessary. You’re looking for specific failure patterns:
Null pointer exceptions (objective, binary)
SQL injection vulnerabilities (pattern-matching against known exploits)
Authentication bypasses (checklist verification)
Hard-coded secrets or API keys (searchable)
Missing error handling (structural analysis)
Deviations from the company’s “Gold Standard Library”—a curated set of approved implementation patterns for common operations
Your judgment scope is bounded. You don’t evaluate architectural decisions—those escalate to Rung 3 engineers. You don’t assess business logic alignment—that’s product management’s domain. You verify technical correctness within explicit parameters.
The cognitive mechanism:
In Month 1, you work from checklists: “Does this authentication implementation match our approved OAuth pattern? Yes/No.” By Month 3, you’ve seen 1,500+ examples. You start recognizing patterns: “This implementation will fail when the access token expires.” By Month 6, you’ve internalized failure modes that would have taken traditional juniors three years to encounter organically.
Data from the Jellyfish Copilot Dashboard confirms that junior developers currently see only 4% speed improvement from AI tools because they lack the verification skills to trust the output. But when structured as Verification Specialists—trained explicitly on pattern recognition rather than manual implementation—that 4% becomes 300-500% through volume amplification.
The economic value:
A Verification Specialist shipping 50 verified implementations per week is producing $150,000-$200,000 in annualized value at a $90,000 cost. But that’s not why you hire them. You hire them because in 18 months they’ll be ready for Rung 2, and in 36 months they’ll be architecting systems that currently require $250,000 seniors.
You’re not paying for Year 1 productivity. You’re buying a future senior at a 70% discount.
Rung 2: The Component Architect (Year 1-2)
Job title: AI-Augmented Component Architect
Salary range: $120,000-$150,000
Core responsibility: Design features where AI implements, human evaluates
What changes:
Your judgment scope expands from “Is this code correct?” to “Which approach is right?” You’re no longer verifying against checklists—you’re making architectural decisions.
A product manager requests a new feature: real-time collaborative editing for a document platform. In the traditional model, a mid-level engineer would spend 40 hours implementing one approach. In the AI-augmented model, you spend 2 hours designing three approaches:
Option A: Operational transformation (complex, battle-tested)
Option B: Conflict-free replicated data types (simpler, emerging standard)
Option C: Hybrid with server-side reconciliation (fallback safety)
You prompt AI to generate implementations for all three. By end of day, you have working prototypes. You evaluate:
Latency under load (benchmarking)
Edge case handling (what happens when network partitions?)
Maintainability (which will your team understand in 2028?)
Technical debt (which creates the least coupling?)
The AI couldn’t make this decision. It can generate all three options flawlessly. But it can’t evaluate context-specific tradeoffs: your team’s expertise, your infrastructure constraints, your product roadmap.
The wisdom compression:
In a traditional 2-year progression, you’d implement 50-75 features, making the architectural choice after designing each one extensively. As a Component Architect with AI, you evaluate 200-300 architectural choices because the implementation cost collapsed to near-zero. You see the consequences—in staging, in production, in maintenance burden—across 4x more scenarios.
By Year 2, you have pattern recognition that traditionally required Year 5.
Rung 3: The System Architect (Year 3-4)
Job title: Senior Software Engineer (System Ownership)
Salary range: $180,000-$250,000
Core responsibility: Own architectural integrity across multi-team systems
The judgment scope:
You’re no longer designing individual features. You’re asking uncomfortable questions early:
“This microservice decomposition looks clean, but we’ll have 47 network calls on the critical path. What happens when AWS us-east-1 hiccups?”
“AI generated this database schema perfectly—for 10,000 users. What breaks at 10 million?”
“This architecture optimizes for current requirements. What constraints does it create for the roadmap we know is coming in Q3?”
You’re operating in the domain where AI struggles: second-order effects, scaling discontinuities, organizational dynamics, regulatory compliance, legacy system integration.
The experience you bring:
You’ve reviewed 5,000+ implementations (Rung 1). You’ve designed 300+ components (Rung 2). You’ve seen how technical debt compounds, how “temporary solutions” ossify, how systems fail under load. That pattern recognition is now intuitive.
When AI suggests an architecture, you can immediately identify whether it’s “textbook correct” or “production-ready.” That distinction—the difference between code that works in demo environments and code that survives contact with reality—is the expertise companies are currently paying $250,000-$400,000 to acquire externally.
You represent that expertise, developed internally in 3-4 years instead of 7-10 years, because AI compressed your feedback loops.
Rung 4-5: The Technical Leader (Year 5+)
Job title: Principal Engineer / VP of Engineering
Salary range: $250,000-$600,000+
Core responsibility: Organizational strategy and culture
You set the technical direction. You decide:
Which problems the company should solve with AI vs. which require human judgment
How to structure teams for AI-augmented workflows
What the “Gold Standard Library” contains
When to accrue technical debt deliberately vs. when to refactor
How to balance innovation velocity with system stability
This is the accountability that can’t be automated. When the system fails, you own the decision. When the architecture needs to evolve, you make the call. When the board asks “Should we build or buy?”, your judgment determines the company’s technical future.
The difference:
A Principal Engineer hired externally in 2030 will command $600,000-$800,000 in a constrained market. A Principal Engineer developed through your Judgment Ladder cost $1.2M total from Rung 1 to Rung 5 (5 years × $240K average fully-loaded cost), represents zero poaching risk, holds institutional knowledge, and arrived at this level 3-5 years faster than traditional progression.
ROIJudgment Ladder=External Principal Cost (2030)Internal Development Cost (2025-2030)=$3.0M (5 years × $600K)$1.2M≈2.5×\text{ROI}_{\text{Judgment Ladder}} = \frac{\text{External Principal Cost (2030)}}{\text{Internal Development Cost (2025-2030)}} = \frac{\$3.0M \text{ (5 years × \$600K)}}{\$1.2M} \approx 2.5\timesROIJudgment Ladder=Internal Development Cost (2025-2030)External Principal Cost (2030)=$1.2M$3.0M (5 years × $600K)≈2.5×
And that calculation doesn’t account for the optionality value: having a bench of Rung 3-4 engineers when competitors face succession crises.
The Bounded Domain Problem and the Gold Standard Solution
The objection arrives immediately: “Juniors can’t audit code. They don’t know what ‘right’ looks like.”
True. Which is why the Verification Specialist role requires explicit infrastructure.
The Gold Standard Library
Every company implementing the Judgment Ladder must build a curated reference implementation library. This is not documentation—it’s working code representing approved patterns:
Authentication: OAuth 2.0 + PKCE implementation with refresh token rotation
Database queries: Parameterized statements with connection pooling
API design: RESTful endpoints with rate limiting and idempotency keys
Error handling: Structured logging with trace IDs and exception chaining
Security: Input validation, output encoding, CSP headers
When a Verification Specialist reviews AI-generated authentication code, they’re not evaluating from first principles. They’re comparing against the Gold Standard: “Does this implementation match our approved OAuth pattern? If it deviates, is there documented justification?”
This transforms verification from “subjective architectural judgment” (requires senior expertise) to “pattern matching against known-good examples” (trainable in months).
Progressive Complexity with Real-Time Escalation
Weeks 1-4: Verification against explicit checklists
Binary decisions: Present/absent (error handling exists: yes/no)
Tool-assisted: SonarQube flags security issues automatically
Success metric: 90%+ checklist completion accuracy
Months 2-3: Pattern matching against Gold Standards
Comparative analysis: Does this match approved patterns?
Deviation documentation: Why did AI choose this approach?
Success metric: 80%+ correct identification of pattern violations
Months 4-6: Architectural reasoning with senior backup
Edge case analysis: What breaks under load?
Technical debt assessment: What maintenance burden does this create?
Escalation protocol: Flag concerns, discuss with Rung 3, implement decision
Success metric: 70%+ of escalations result in code changes
By Month 12: Autonomous verification of 80% of implementations, intelligent escalation of the 20% requiring senior architectural judgment.
The key insight: You’re not asking juniors to possess judgment. You’re training judgment through systematic exposure to failure modes, with safety rails.
The Prisoner’s Dilemma: Why Rational Actors Choose Collectively Irrational Outcomes
If the economic case is this compelling, why are only 6% of companies executing this model?
Because talent development is a non-excludable good in a liquid labor market. Consider the game theory:
Company A’s decision matrix:
Option 1: Invest $330,000 developing a junior to Rung 3 over 3 years
40% chance they leave at Year 2 (industry-average attrition)
Expected value: $330K × 0.60 = $198K
Risk-adjusted cost per retained engineer: $550K
Option 2: Don’t train, poach Rung 3 engineers from companies that do train
Immediate capability, no training risk
Market rate: $200K/year base
3-year total: $662K (with 10% annual increases)
Current equilibrium: Training is already cheaper ($550K vs $662K). But Company A knows that Company B will poach their trained engineers at Year 2. So the dominant strategy is: don’t train, free-ride on others’ investment.
Nash Equilibrium: No one trains. Senior pool depletes. Prices spike.
2026 reality: This dynamic is already playing out. Senior salaries increased 8-15% annually in 2024-2025. Platform engineers command $182K-$251K. Cybersecurity architects reach $400K. AI/ML specialists earn 12% premiums over generalists.
2030 projection: If junior hiring stays suppressed 20%, the senior shortage becomes acute. Companies bid $600K, then $800K, desperate for expertise that doesn’t exist. Even accounting for 40% attrition risk, internal development becomes dramatically cheaper:
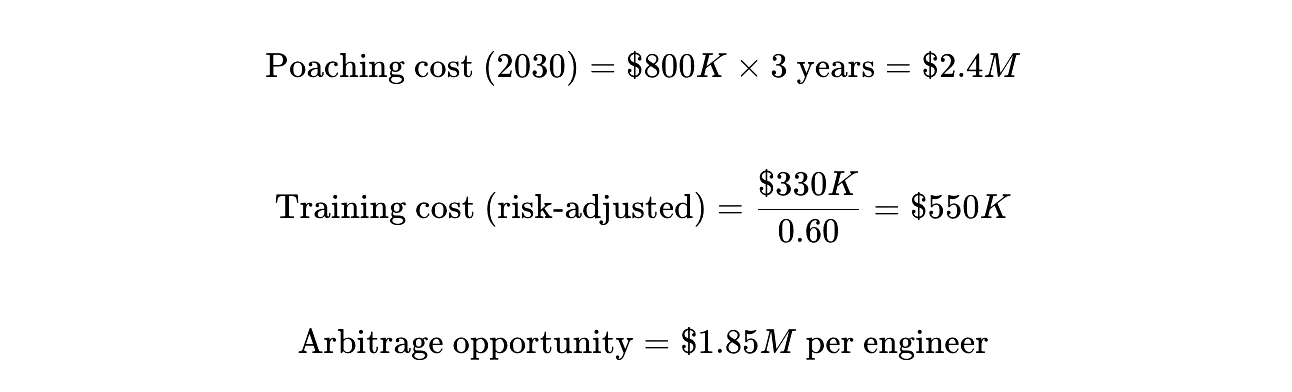
But you can’t start training in 2028 when the crisis becomes obvious. The lag time is 3-5 years. The companies that start building Judgment Ladders in 2026 will have Rung 3-4 engineers in 2029-2031 precisely when competitors face catastrophic shortages.
The 6% who figured this out: They’ve solved the prisoner’s dilemma through retention mechanisms:
Stock vesting over 4 years (golden handcuffs)
Clear progression paths (internal promotion trumps lateral moves)
Learning opportunities (people stay for skill development)
Culture of ownership (psychological investment beyond compensation)
If you can reduce attrition from 40% to 15%, the math flips decisively:
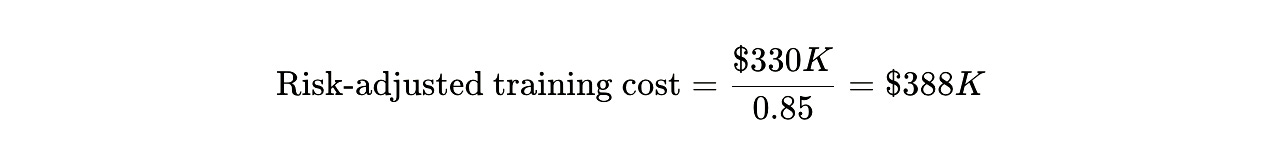
Now internal development is $274K cheaper than poaching even at current market rates, and $2.0M cheaper than projected 2030 rates.
The 10-20-70 Principle Applied to Talent Architecture
Research from Boston Consulting Group and McKinsey consistently shows that AI transformation success depends on resource allocation:
10% - AI algorithms and model selection
20% - Data infrastructure and technical integration
70% - People, processes, and organizational transformation
The companies achieving 5%+ EBIT impact from AI (the 6% high performers) honor this allocation religiously. The 61% stuck in “pilot purgatory” invert it—spending 70% on vendor selection and tool evaluation, 20% on technical implementation, 10% on actually preparing humans to work differently.
Applied to the Judgment Ladder:
The 10%: Tool Selection
Choose AI coding assistants (GitHub Copilot, Cursor, etc.)
Select verification tools (SonarQube, CodeScene, automated security scanners)
Establish LLM infrastructure
Time investment: 4-6 weeks upfront, quarterly reviews
The 20%: Infrastructure & Process Design
Build the Gold Standard Library (curated reference implementations)
Create verification dashboards (track review accuracy, escalation rates)
Design progression criteria (when does a Verification Specialist become a Component Architect?)
Establish escalation protocols (how do Rung 1 engineers flag concerns to Rung 3?)
Implement automated quality gates (linters, security scanners, test coverage)
Time investment: 3-6 months initial build, ongoing maintenance
The 70%: People & Organizational Transformation
Redesign job descriptions for Rung 1-5 roles
Train Rung 3+ engineers to mentor verification skills (not just coding skills)
Create feedback loops (how do juniors learn from their mistakes?)
Build retention mechanisms (career progression clarity, learning budgets, equity structures)
Cultural transformation (from “AI replaces humans” to “AI accelerates human judgment development”)
Time investment: 12-24 months, continuous iteration
The companies that fail spend 6 months evaluating which AI tool to purchase, implement it in 2 weeks, and wonder why adoption stalls. The companies that succeed spend 2 weeks choosing a tool, then 18 months building the organizational capacity to use it effectively.
The Medical Residency Model: Manufacturing Artificial Struggle
Here’s the cognitive science problem that makes this difficult: Traditional junior engineers developed expertise through struggle. Debugging a subtle race condition at 2 AM. Wrestling with CSS quirks for hours. Manually implementing complex business logic and discovering why the “obvious” approach fails.
AI removes this struggle. A junior can now prompt “implement authentication with JWT tokens” and receive working code in 30 seconds. No struggle. No debugging. No learning.
This is the “Easy Button Problem”: When the path from problem to solution is frictionless, the brain doesn’t encode the pattern. You need cognitive load—not too much (overwhelm) or too little (boredom), but the optimal difficulty that forces active problem-solving.
Medical education solved this decades ago with the residency system. Doctors don’t learn by reading textbooks—they learn by treating patients under supervision. The “struggle” is real (patient care) but bounded (attending physician oversight).
Software engineering is adopting the same model, but the “patients” are AI-generated implementations:
Sandbox Simulations (Controlled Failure)
Month 1 training: Verification Specialists work exclusively in sandbox environments. They’re given deliberately flawed AI implementations—code that compiles but contains security vulnerabilities, performance issues, or subtle logic errors. Their task: identify all flaws before “deploying to production” (actually just a staging environment).
Success metric: 90% flaw detection rate before graduation to production review.
The learning: Pattern recognition through concentrated exposure. In their first month, they see 200+ implementations containing every common failure mode. By Month 3, they’ve internalized what SQL injection, XSS, authentication bypass, and race conditions look like.
Socratic AI Mentors (Guided Discovery)
When a Verification Specialist misses a bug, the system doesn’t just tell them the answer. It asks questions:
“You approved this authentication implementation. What happens if the JWT token expires during a long-running request?”
“This database query works with 100 users. Walk through what happens with 1 million users.”
“The code handles the happy path. What are three failure modes you should test?”
This is the “Artificial Struggle”—deliberate cognitive load that forces active problem-solving rather than passive absorption. Research on learning shows that retrieval practice (being forced to recall information) creates 50% stronger memory encoding than passive review.
Evaluation-Driven Development
Before a Verification Specialist reviews any code, they must define success criteria:
“This authentication implementation should:
Prevent SQL injection (test: input validation with malicious strings)
Handle token expiration gracefully (test: artificial timeout scenarios)
Rate-limit login attempts (test: automated brute force simulation)
Log authentication events (test: verify structured logs exist)”
Then they evaluate whether AI-generated code meets these criteria. This shifts the cognitive task from “Does this look right?” (pattern matching) to “Does this meet explicit requirements?” (systematic verification).
The result: Verification Specialists aren’t passively accepting or rejecting AI output. They’re actively reasoning about correctness through formal evaluation. This is the expertise that becomes intuitive by Rung 3.
The Economic Proof: Salary Inflation vs. Pipeline Investment
Let’s make this concrete with 2026 market data and 2030 projections:
Current State (2026)
San Francisco median software engineer: $180,659
Senior/Principal range: $183,000-$298,000
AI/ML specialist premium: +12% over generalists
Platform engineer range: $182,000-$251,000
Cybersecurity architect range: $143,000-$400,000
Entry-level market:
Bootcamp graduates: $70,000-$85,000
CS graduates (no experience): $80,000-$95,000
CS graduates (1-2 internships): $95,000-$110,000
The Talent Scarcity Tax
Companies exclusively hiring externally face compounding costs:
Year 1: Hire senior at $200K
Year 2: Retention raise (8%) = $216K
Year 3: Market adjustment (10%) = $238K
Year 4: Competing offer defense (15%) = $274K
Year 5: Market rate reset = $300K+
5-year total compensation: $1.228M minimum
Alternative scenario (Judgment Ladder):
Year 1: Hire junior at $90K, Rung 1
Year 2: Promote to Rung 2 at $130K
Year 3: Rung 2 at $140K
Year 4: Promote to Rung 3 at $180K
Year 5: Rung 3 at $195K
5-year total compensation: $735K
Savings per engineer: $493K over 5 years
But the real value is strategic positioning:
2030 Labor Market Projections
If current trends continue:
Senior shortage: 85.2 million global software engineer deficit (UN projections)
Salary inflation: 15-20% annually in constrained specialties
Platform engineers (2030): $350K-$500K
System architects (2030): $400K-$600K
Principal engineers (2030): $600K-$900K
Market dynamics:
Companies that suppressed junior hiring 2024-2026 face succession crises as seniors retire
No amount of money can purchase expertise that doesn’t exist in sufficient quantities
Bidding wars drive total compensation to unsustainable levels
Quality declines as desperate companies hire less-qualified candidates at inflated prices
Companies with Judgment Ladders:
Internal pipeline producing 15-20 Rung 3-4 engineers annually
Average fully-loaded cost: $220K (compared to $500K+ external)
Zero poaching risk (promoted from within, culturally invested)
Institutional knowledge preserved across generations
Competitive advantage: can scale engineering org while competitors stagnate
The Arbitrage Opportunity
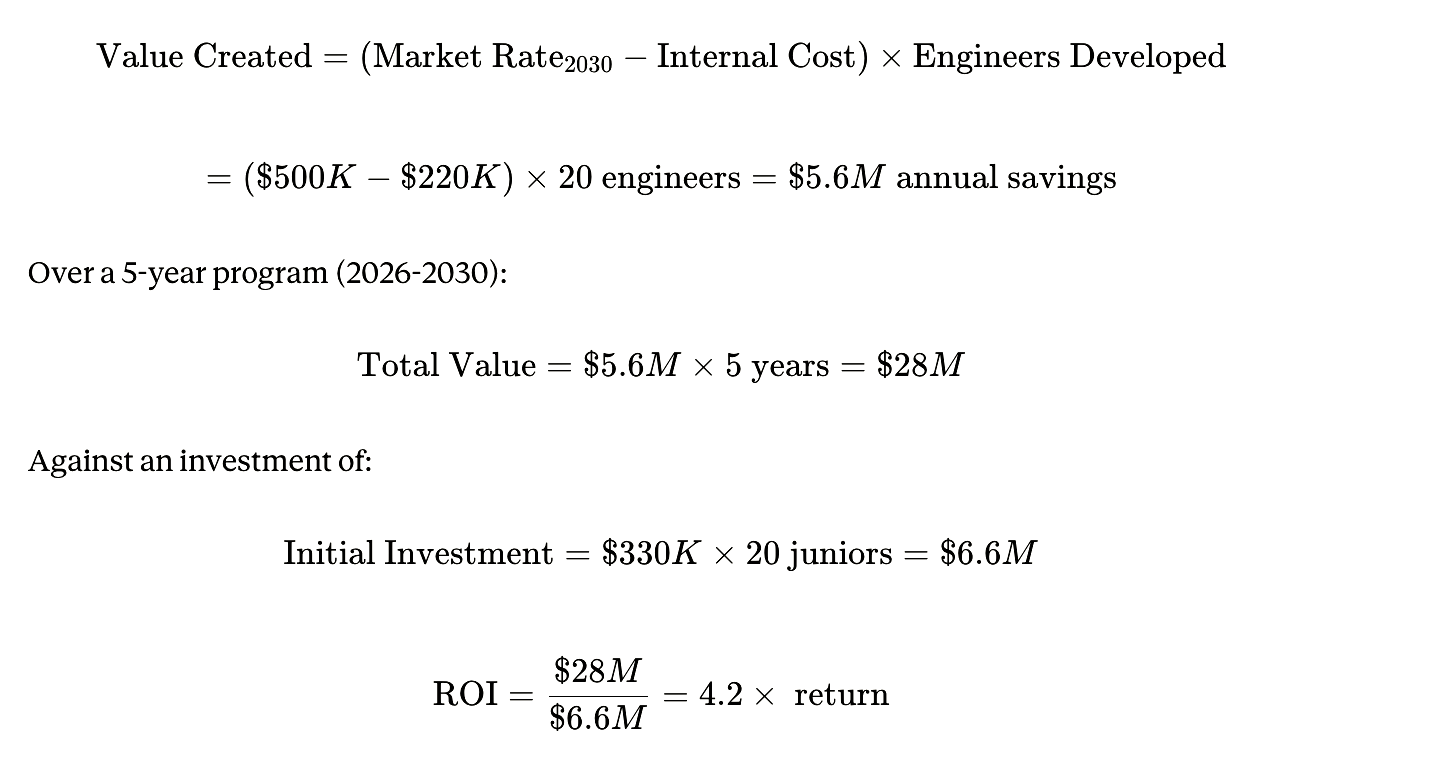
This is the 4x advantage that separates the 6% of high performers from the 94% walking into crisis. It’s not a one-time delta—it’s a compounding strategic moat that becomes insurmountable by 2030.
The 2030 Bifurcation: Winners and Hollow Organizations
The strategic landscape of 2030 will be defined entirely by decisions made in 2024-2026.
The Winners: Supercharged Progress
These are the companies that recognized AI as an accelerant, not a replacement:
Talent profile:
Deep bench of Rung 3-4 engineers (25-35 years old, 3-7 years experience)
Seniors focused on architecture and strategy, not verification
Juniors producing immediate value while learning at 10x traditional speed
Low attrition (15-20%) due to clear progression and learning opportunities
Operational characteristics:
Ship features 2-3x faster than competitors (AI generation + human judgment)
Deploy with 50% fewer production incidents (better verification)
Technical debt under control (Verification Specialists catch issues early)
Can scale engineering org linearly with business growth
Financial performance:
50% higher revenue growth (compound effect of faster shipping × fewer incidents)
60% higher total shareholder return (research from BCG on AI transformation ROI)
4x competitive advantage in talent costs ($220K vs $500K+ for equivalent capability)
Strategic positioning:
Talent moat: competitors can’t poach what you built internally
Institutional knowledge: engineers who grew up in your systems
Scalability: can double engineering org while competitors face hiring freezes
Optionality: excess capacity to pursue strategic opportunities
The Losers: Hollow Organizations
These are the companies that chose the false choice—cutting juniors for short-term P&L optimization:
Talent profile:
Thin layer of expensive seniors (45-60 years old, approaching retirement)
Missing middle layer (no mid-level engineers, nobody to promote)
Zero juniors (eliminated 2024-2026 for “efficiency”)
High attrition (30-40%) as seniors burn out or get poached
Operational characteristics:
Seniors drowning in verification work (35% of time reviewing AI output)
Can’t ship faster despite AI tools (verification bottleneck)
Accumulating technical debt (no one to review code carefully)
Cannot scale (no junior pipeline to grow from)
Crisis timeline:
2028: First seniors retire, no replacements available internally
2029: Bidding wars for scarce external talent, salaries hit $600K+
2030: Succession crisis becomes acute, multiple key systems have single points of failure
2031: Production incidents increase as overloaded seniors make mistakes
2032: Board forces emergency measures: offshore entire teams, acquire competitors for talent, merge with better-positioned companies
Financial performance:
Stagnant revenue growth (can’t ship faster, losing competitive races)
Declining margins (senior salary inflation + production incident costs)
Talent crisis premium: paying 4x for external hires vs what internal development would have cost
Strategic paralysis: can’t pursue growth opportunities without engineering capacity
The Divergence Is Already Visible
You don’t need to wait until 2030 to see this bifurcation beginning. The data from 2025 already shows it:
Companies investing in AI-augmented talent development (6% of orgs):
5%+ EBIT impact from AI initiatives
$3.70-$10.30 return per dollar invested in AI
38% reinvesting productivity gains into upskilling
47% expanding AI capabilities
Revenue growth 2-4x industry average
Companies stuck in pilot purgatory (61% of orgs):
Zero measurable ROI from AI initiatives
55% already regret AI-driven layoffs
Quietly rehiring (often offshore or at lower quality)
Productivity paradox: AI tools deployed but no improvement in output
The next 4 years will determine which category you’re in.
What You Do Monday Morning
You’re convinced. The Judgment Ladder makes strategic, economic, and operational sense. How do you actually implement it?
Phase 1: Audit Current State (Weeks 1-2)
Map your existing talent to the Judgment Ladder:
For each engineer, assess:
What level of judgment do they currently exercise? (Rung 1-5)
What level should they be at based on experience? (gap analysis)
Who can mentor Rung 1-2 engineers? (Rung 3+ only)
Count your gaps:
How many Rung 1-2 positions should you have? (15-25% of engineering org)
How many do you actually have? (probably close to zero if you cut juniors)
What’s your succession pipeline? (when Rung 4-5 engineers leave/retire, who replaces them?)
Calculate your talent crisis timeline:
Average age of Rung 3+ engineers: ____
Expected retirement/attrition over next 5 years: ____
Current pipeline filling that gap: ____
Deficit in 2030: ____ senior engineers short
If that number is greater than zero, you have 3-5 years before the crisis becomes acute. You cannot fix this problem in 2029. You must start now.
Phase 2: Design the Gold Standard Library (Months 1-3)
Assemble a task force:
2-3 Rung 4-5 engineers (set architectural standards)
1 security specialist (define security patterns)
1 DevOps/SRE (define operational patterns)
Create reference implementations for:
Authentication/Authorization:
OAuth 2.0 + PKCE flow
JWT token management (generation, validation, refresh)
Role-based access control (RBAC) implementation
Session management and timeout handling
Data Access:
Parameterized SQL queries (prevent injection)
ORM usage patterns (when to use, when to avoid)
Database connection pooling
Transaction management
Caching strategies
API Design:
RESTful endpoint structure
Request validation and sanitization
Response formatting (JSON standards)
Error handling and status codes
Rate limiting and throttling
Idempotency key handling
Security:
Input validation patterns
Output encoding (prevent XSS)
CSRF protection
Content Security Policy headers
Secrets management (never hardcode)
Error Handling:
Structured logging with trace IDs
Exception hierarchy and propagation
User-facing vs internal errors
Retry logic and circuit breakers
Each pattern includes:
Working implementation (copy-paste ready)
Anti-patterns (what NOT to do, with examples)
Test cases (how to verify correctness)
Documentation (why this pattern, what tradeoffs)
Maintenance: Quarterly reviews, updates when patterns change, version control with change logs.
Phase 3: Write AI-Native Job Descriptions (Month 2)
Rung 1: Software Verification Specialist
We’re looking for engineers who want to develop architectural judgment by working with AI tools. You’ll review 50-100 AI-generated implementations weekly, learning to spot subtle bugs, security vulnerabilities, and architectural issues that even experienced engineers miss. By the end of Year 1, you’ll have seen more code patterns than traditional juniors see in 3 years.
Responsibilities:
Review AI-generated code against our Gold Standard Library
Verify security, correctness, and maintainability
Use automated tools (SonarQube, CodeScene) to catch technical debt
Escalate architectural concerns to Rung 3 engineers
Document patterns: what failure modes did you catch, how did you identify them?
Requirements:
Can read and understand code (any language, we’ll train specifics)
Security awareness (know what SQL injection, XSS, CSRF mean)
Critical thinking (don’t trust AI output, verify everything)
Learning mindset (you’ll see 10,000+ code examples in Year 1)
What you’ll learn:
Pattern recognition for code quality and security (develops intuition)
Architectural thinking (by reviewing architectural decisions daily)
System design (see how components fit together)
Professional software practices (testing, documentation, version control)
Career path:
Year 1: Verification Specialist ($90K) - review and verify
Year 2: Component Architect ($130K) - design and evaluate
Year 3-4: System Architect ($180K) - own multi-team systems
Year 5+: Principal Engineer ($250K+) - set technical direction
No AI will make you obsolete. We’re teaching you to be the human that makes AI useful.
Phase 4: Implement Progressive Training (Months 3-6)
Month 1: Sandbox simulation
100% of work in non-production environments
Deliberately flawed implementations (training data)
Checklist-based verification (binary decisions)
Daily feedback from Rung 3 mentors
Goal: 90% flaw detection rate
Month 2-3: Pattern matching
50% sandbox / 50% production review (with oversight)
Compare implementations to Gold Standards
Identify deviations and document reasoning
Weekly mentorship sessions
Goal: 80% correct pattern identification
Month 4-6: Architectural reasoning
20% sandbox / 80% production review
Identify edge cases and scaling issues
Escalate concerns with technical justification
Design verification test cases
Goal: 70% of escalations result in code changes (showing good judgment)
Month 7-12: Autonomous operation
Verify 80% of implementations independently
Escalate 20% that require senior architectural judgment
Begin mentoring new Rung 1 hires
Start designing simple components (transition to Rung 2)
Phase 5: Measure, Iterate, Scale (Ongoing)
Key metrics to track:
Verification Quality:
What % of bugs do Rung 1 engineers catch before production?
What % of their approvals later cause incidents?
How does this compare to senior review rates?
Development Velocity:
How many implementations can one Rung 1 engineer verify per week?
How does this change over their first 12 months?
What’s the ROI comparison: Rung 1 verification vs senior verification?
Progression Speed:
How long from Rung 1 → Rung 2? (target: 12-18 months)
How long from Rung 2 → Rung 3? (target: 18-24 months)
Total time Rung 1 → Rung 3? (target: 36-48 months vs 60-84 months traditional)
Retention:
What % of Rung 1 hires stay through Rung 3? (target: 70%+)
Why do people leave? (compensation, culture, learning opportunities?)
How do retention rates compare to industry average?
Business Impact:
Production incidents attributable to AI-generated code
Technical debt metrics (code duplication, complexity, test coverage)
Time-to-market for new features (generation speed × verification quality)
Total engineering cost per feature delivered
Iteration criteria:
If verification quality is low (<70% bug detection):
Add more sandbox training time
Improve Gold Standard Library documentation
Increase mentorship frequency
If progression is slow (>18 months Rung 1→2):
Add more complex verification challenges
Provide architectural training earlier
Create more opportunities for component design
If retention is low (<60% through Rung 3):
Review compensation competitiveness
Strengthen career progression clarity
Improve learning opportunities and culture
Phase 6: Build Retention Mechanisms (Continuous)
The Judgment Ladder only works if people stay long enough to climb it. You need:
Financial golden handcuffs:
Equity vesting over 4 years (backend-loaded if possible)
Annual retention bonuses at each rung transition
Clear compensation progression (publish the Rung 1-5 salary bands)
Career progression clarity:
Explicit criteria for each rung promotion (not subjective “readiness”)
Timeline expectations (12-18 months per rung, not indefinite)
Transparent process (what skills must you demonstrate to advance?)
Learning and development:
Conference budget (2-3 per year)
Training budget ($3K-5K annually)
Internal tech talks (learn from Rung 4-5 engineers)
External mentorship (industry connections)
Cultural investment:
Psychological safety (safe to escalate concerns, ask “dumb” questions)
Ownership and autonomy (even Rung 1 engineers own verification quality)
Recognition (public credit for catching critical bugs)
Community (junior cohorts support each other)
The research is clear: People don’t leave primarily for compensation (though that matters). They leave when they can’t see a future, when learning stops, when they feel undervalued. The companies achieving 85%+ retention through Rung 3 excel at all four categories above.
The Accountability That Can’t Be Automated
We return to where we started: the METR chart showing AI completing tasks in minutes that once took hours.
That chart is accurate. And irrelevant.
Because software engineering was never primarily about typing code. It was always about making decisions under uncertainty:
Is this the right architecture for our scale?
What happens when this assumption breaks?
Should we ship now with technical debt or wait for the better solution?
What are we optimizing for: speed, cost, reliability, maintainability?
Who is responsible when this fails at 2 AM on Saturday?
AI can generate options. It cannot choose between them when the tradeoffs are context-specific, when the constraints are organizational, when the consequences compound over years.
That’s judgment. And judgment is developed through:
Pattern recognition - seeing thousands of decisions and their consequences
Contextual reasoning - understanding how your specific systems behave
Accountability - owning the outcome when your decision proves wrong
The Judgment Ladder accelerates all three. Rung 1 engineers see 10,000 implementations in Year 1 (pattern recognition). Rung 2 engineers make 300 architectural decisions in Year 2 (contextual reasoning). Rung 3 engineers own production systems in Year 3-4 (accountability).
The alternative is the slow collapse most companies are currently choosing:
Cut juniors → Senior shortage → Bidding war → Crisis hiring → Quality decline → Production incidents → Customer loss → Strategic paralysis
The math is unforgiving. The timeline is shorter than you think. And the companies that understand this before their competitors have already won the 2030 talent war.
The Flight Simulator Is Ready
You are standing at the inflection point. The decision you make in 2026 determines your talent position in 2030.
The METR chart went viral because it tells a simple story: AI is getting exponentially better at completing tasks. But the complete story is more complex and more urgent:
AI compresses implementation time. True.
AI compresses wisdom development time. Also true, but only if you design for it.
AI eliminates the need for juniors. False. It eliminates one training method and requires a new one.
AI makes seniors obsolete. False. It makes senior judgment more valuable and more scarce.
Most companies will act rationally. False. They’ll optimize locally and create collective crisis.
The Judgment Ladder is the flight simulator for software engineering. It compresses 10 years of expertise development into 3-5 years by systematically exposing engineers to thousands of failure modes, architectural decisions, and system consequences—all while producing immediate business value.
The economic case is overwhelming. The strategic advantage is definitive. The implementation blueprint is actionable.
What’s missing is the organizational will to invest in 2026 for 2030 outcomes when quarterly earnings calls demand 2026 results.
The 6% who figured this out are already building their talent moats. The 94% are cutting juniors and wondering why their AI investments aren’t delivering the promised productivity gains.
The vertical line on the METR chart shows capability increasing. The hidden line—the one not graphed—shows judgment capacity decreasing as pipelines collapse.
You can’t purchase judgment that doesn’t exist. You can’t compress five years of development into a crash program when the crisis hits. And you can’t run a technology company in 2030 with senior engineers who learned their craft in 2015.
The flight simulator is ready. The training program is designed. The economic ROI is proven.
The only question is whether you’ll start training pilots while there’s still time—or whether you’ll join the bidding war for non-existent expertise in 2029, wondering why the solution was so obvious in retrospect.
The most important chart in AI went vertical. The most important decision in talent strategy is happening right now.
Choose wisely. The ladder is waiting.