


The $50,000 Question
You are holding a survey instrument that will cost you forty-seven thousand dollars to field. The questions look fine. You’ve read them three times. Your graduate student has read them. Your department chair has read them. Everyone agrees they make sense.
You’re about to press “approve” on the contract with the survey firm.
But here’s what you don’t know: Question seven is going to fail. Sixty-three percent of respondents will speed through it in 4.2 seconds—not enough time to actually read the full text. Question twelve will trigger what methodologists call “straightlining,” where people click the same response repeatedly just to finish. Eighteen percent of your sample will do this. Question fifteen contains a word—”regressive”—that you think everyone understands. They don’t. Lower-education respondents will interpret it as “backward.” Higher-education respondents will read it as a technical tax policy term. You’re measuring two different constructs without knowing it.
By the time you discover these problems, you’ll be staring at data that costs $2.35 per completed response. The agency won’t refund your money. The grant is spent. And somewhere in your dataset, buried in the noise, is a finding that might have mattered—if only you’d asked the question correctly.
The Instrument Problem
Surveys occupy a strange position in the hierarchy of social science methods. They are simultaneously indispensable and deeply flawed, like a thermometer that’s the only way to measure fever but gives you a reading that’s accurate within plus-or-minus 2 degrees on a good day.
The indispensability comes from what surveys can do that nothing else can: measure private opinion at scale. Not the performative declarations people post on social media. Not the revealed preferences of their purchasing behavior or voting records. Private opinion—the thoughts people have but don’t express, the beliefs they hold but actively conceal, the second-order perceptions of what they think everyone else believes.
Consider the canonical example: In 1975, sociologist Hubert O’Gorman discovered that a majority of white Americans privately opposed racial segregation, but believed that most other white Americans still supported it. This gap—between private belief and perceived norm—created what he called “pluralistic ignorance.” People conformed to a norm that no longer existed because they had no way to know the norm had changed. You can’t find pluralistic ignorance in historical newspapers (which show public discourse). You can’t find it in voting records (which show conforming behavior). You need to ask people two questions simultaneously: “What do you think?” and “What do you think others think?” The gap between those answers is the discovery.
But here’s the problem with that thermometer analogy: when your measurement instrument has this much noise, wording becomes everything.
The Noise Landscape
The test-retest reliability for political attitudes sits at r=0.44r = 0.44 r=0.44 to 0.470.47 0.47. Unpack what that correlation coefficient means: if you ask the same person the same question two weeks apart, their answers correlate at 0.45. Squaring that gives you r2=0.20r^2 = 0.20 r2=0.20—which means eighty percent of the variance in their response is... something other than a stable attitude. Measurement error. Mood. Question-order effects. The weather. Whatever they had for breakfast. Random noise that you’re paying $2.35 per data point to collect.
The replication crisis has revealed that when independent research teams attempt to reproduce social science findings, they succeed somewhere between thirty-six and sixty-four percent of the time. Effect sizes shrink by an average of fifty percent on replication. And in some subfields, the replication rate drops to twenty-three percent. These aren’t marginal studies published in predatory journals. These are flagship findings from top-tier venues that fail to reproduce when competent researchers try to verify them.
Meanwhile, your respondents are actively working against you. Thirty-seven to fifty-three percent of online survey respondents engage in what the literature politely calls “speeding”—answering questions faster than it would take to read them. Fifteen to forty percent “straightline” on grid questions, clicking the same response repeatedly. When you exclude these respondents, you’re selecting for the attentive minority, which means your random sample is no longer random. When you include them, you’re averaging in random clicks.
The quality of the instrument—the specific words you use, the order you present them, the response scale you offer—determines whether you’re measuring a real private belief or manufacturing an artifact of your methodology.
What Alternative Methods Cannot Tell You
The alternatives to surveys have become sophisticated. Text analysis can now process the entire Congressional Record from 1873 forward, tracking polarization in legislative speech. Google’s ngram viewer can chart the rise and fall of “environmentalism” across two hundred years of published books. Administrative records can link tax returns to voting behavior, showing how actual income shocks affect partisan choice. Behavioral tracking can monitor how long someone spends reading a news article, what they purchase, where they go.
These methods detected the same trends surveys found—often earlier and cheaper. Polarization in Congress? Text analysis of the Congressional Record found it first, documenting the dramatic shift starting in 1994. Declining religious participation? Census data and church membership records showed this before the General Social Survey confirmed it. Consumer confidence? Credit card spending data tracks this in real-time, no survey required.
But here’s what those methods cannot tell you: In 1979, Donald Kinder and D. Roderick Kiewiet discovered that voters don’t actually vote their pocketbooks. A person’s individual economic circumstances—whether they got a raise, whether they lost their job—had weak correlation with their vote choice. What mattered was their perception of the national economy. Someone thriving personally would vote against the incumbent if they thought the country was suffering. Someone struggling personally would support the incumbent if they believed the nation was prospering.
This finding—termed “sociotropic voting”—requires three measurements that must exist simultaneously in the same dataset: your actual income (observable), your evaluation of your personal situation (first subjective measure), and your evaluation of the national economic condition (second subjective measure). Administrative records give you the first. Behavioral data might proxy the second (spending patterns). But nothing except a survey gives you that third measure—the perception of the collective good—and allows you to correlate all three within the individual mind.
Text analysis of newspapers from 1979 would tell you the national economic narrative. It cannot tell you which individual voters internalized that narrative and which rejected it. The correlation between perception and behavior happens at the individual level, and only surveys sample individuals randomly enough to detect it.
The Wording Sensitivity Trap
If surveys are necessary but fragile, question wording becomes the critical chokepoint. Change one word and the results change.
Consider the mechanics: you’re trying to measure a stigmatized private attitude—say, racial resentment. The modern form doesn’t manifest as explicit hatred but as what Donald Kinder termed “symbolic racism”: the fusion of anti-Black affect with traditional values rhetoric. The survey item reads: “Do you think Black Americans are getting too demanding in their push for equal rights?”
The word “demanding” does the work here. It triggers associations with entitlement, pushiness, violation of norms. A text analysis of Twitter would never flag “demanding” as a racial cue—it appears in countless non-racial contexts. But in a survey about Black Americans, paired with the phrase “too demanding,” it activates the symbolic racism construct.
Now change one word: “Do you think Black Americans are being too aggressive in their push for equal rights?”
“Aggressive” codes differently than “demanding.” It carries physical threat connotations. Different respondents will trip different internal alarms. The correlation with vote choice changes. Your regression coefficient shifts. Your conclusion about how much racial resentment exists in the population shifts.
You won’t know this happened unless you test both wordings. Testing both wordings on humans means doubling your pilot study cost. Most researchers don’t have the budget. So they guess. Sometimes they guess wrong. And a forty-seven thousand dollar dataset becomes a monument to a question that didn’t measure what they thought it measured.
The Synthetic Audit
Here’s the methodological arbitrage: Large language models are trained on the entire survey methodology literature. They’ve ingested decades of research on social desirability bias, question-order effects, response scale validation, and stereotype activation. They don’t “know” what humans privately think—but they do know what survey methodologists have discovered about how question wording influences responses.
The proposal is simple: Before you spend forty-seven thousand dollars asking one thousand real humans your questions, spend forty-seven dollars asking one thousand synthetic personas.
The process works like this:
Step One: Generate Demographic Diversity
Build synthetic personas using the empirical priors. Draw from the Big Five personality dataset’s one million responses. Cross-reference with Census demographics for geographic distributions. Layer in political attitudes from historical survey data. Create personas that span the actual population distribution: the 22-year-old progressive in Brooklyn with high Openness, the 67-year-old conservative in rural Alabama with high Conscientiousness, the 45-year-old moderate in suburban Phoenix with middling scores across all dimensions.
You generate one thousand of these. It takes three minutes.
Step Two: Administer the Survey
Each synthetic persona receives your instrument. The LLM, conditioned on the persona’s attributes, generates responses. You collect one thousand completed surveys in approximately twenty minutes. Cost: somewhere between ten and fifty dollars, depending on your API pricing tier.
Step Three: Run the Diagnostics
Now the statistical analysis reveals what human pilots rarely catch:
Social desirability cascade: When eighty-five percent of synthetic personas—across all political ideologies—give the “socially acceptable” answer to question seven, you’ve written a question that measures virtue signaling, not private belief. The flag appears in your output: “Warning: Low variance. Possible social desirability bias.”
Comprehension failure: When personas with graduate-level education interpret question twelve differently than personas with high-school education, you’ve created a measurement that isn’t comparable across groups. The synthetic audit outputs the divergent interpretations, showing you exactly where the misunderstanding occurs.
*Stereotype activation*: When you analyze response patterns, you discover that question fifteen produces answers that correlate r=0.87r = 0.87 r=0.87 with persona age—but your theoretical model predicted only r=0.30r = 0.30 r=0.30 based on literature. Either you’ve discovered something new (unlikely), or your question is triggering age stereotypes rather than measuring the construct. The personas are functioning as cognitive model amplifiers, revealing what the question actually activates.
Step Four: The Ensemble Cross-Validation
You don’t trust a single LLM. You run the same audit through GPT-4, Claude, and Gemini simultaneously. Where all three flag the same questions, you investigate. Where they diverge, you note which issues are genuinely ambiguous versus which are artifacts of one model’s training.
The ensemble generates specific revision suggestions:
“Question 7: Remove ‘too’ from ‘too demanding’—creates leading bias”
“Question 12: Define ‘regressive’ or use simpler term ‘backward-looking’”
“Question 15: Age correlation suggests stereotype activation—consider neutral phrasing”
Step Five: Iterate Until Clean
You revise. You run the audit again. The warnings decrease. When your instrument passes the synthetic audit with minimal flags, you run one human pilot—not three. You’ve used the synthetic personas to do the heavy lifting of identifying obvious problems. The human pilot confirms there are no unexpected issues the synthetics missed.
Your total pre-testing cost: five thousand dollars instead of ten thousand. More importantly: your forty-seven thousand dollar main survey is now fielding questions you have high confidence actually measure what you think they measure.
The Fundamental Distinction
This approach works because it respects a bright epistemological line: LLMs cannot tell you what humans privately think. But they can tell you whether your questions are well-designed to elicit private thoughts rather than public performances.
The five categories of private opinion that surveys uniquely capture each have corresponding question-design failures that synthetic audits can detect:
Unexpressed opinion: You have a view but haven’t posted it anywhere. Audit catches: Questions that suggest the “right” answer instead of eliciting genuine views.
Unobservable mental states: Feelings that don’t reliably map to behavior. Audit catches: Questions that conflate behavior with belief (”Do you support X?” vs. “Would you do X?”)
Stigma-managed attitudes: Views you conceal due to social desirability. Audit catches: Wording that signals which answer is socially acceptable.
Second-order beliefs: What you think others believe. Audit catches: Confusion between “what do you think?” and “what do most people think?”
Counterfactual preferences: What you’d want under hypothetical conditions. Audit catches: Scenarios with too many assumptions, forcing respondents to guess.
The mathematics of survey reliability makes this approach rational. If your baseline test-retest correlation is r=0.45r = 0.45 r=0.45, then:
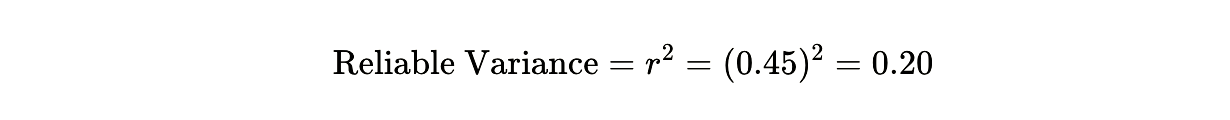
Eighty percent of your measurement is noise. If a twenty-dollar synthetic audit can reduce that noise by even five percentage points—bringing reliability from r=0.45r = 0.45 r=0.45 to r=0.50r = 0.50 r=0.50—you’ve increased your reliable variance from twenty percent to twenty-five percent. That’s a twenty-five percent improvement in signal quality.
The expected value calculation is straightforward:
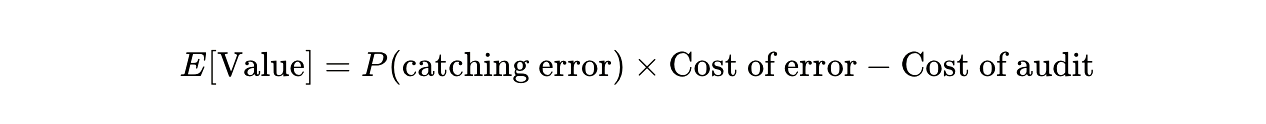
If the synthetic audit has a sixty percent chance of catching a wording problem that would corrupt your forty-seven thousand dollar survey, and the audit costs forty-seven dollars:
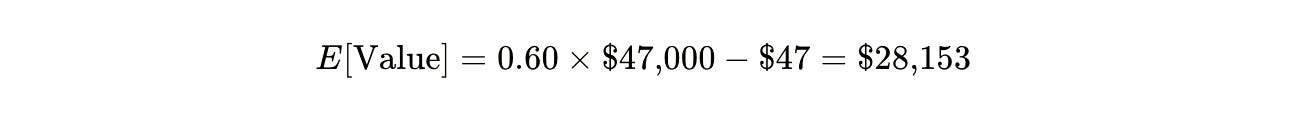
The expected value of running the audit is twenty-eight thousand dollars. You’d need to be remarkably confident in your question-writing to skip it.
The Resistance
Survey methodologists have professional reasons to be skeptical. Synthetic personas have been oversold. Companies claim they can “replace human respondents entirely” or “eliminate the need for expensive pilots.” These claims are false and methodologically reckless. LLMs generate stereotypes, not the variance-rich distributions of human populations. They can’t measure private opinion. They shouldn’t be trusted to replace the human survey.
But that’s not what this is.
This is quality assurance. This is catching the typo before you go to print, not replacing the printing press. When Boeing uses computer simulations to test wing stress before building the physical prototype, nobody accuses them of “replacing engineering.” The simulation is a tool to make the real thing better.
The same logic applies here. The synthetic audit doesn’t replace human pilots. It makes them more efficient. Instead of running three rounds of human pilots at five thousand dollars each, you run ten rounds of synthetic audits at forty dollars each, then one human pilot to confirm. You’ve done more iteration, caught more problems, and spent less money.
The intellectual honesty matters. You’re not claiming the synthetics know what humans think. You’re claiming they know what survey methodologists have learned about question design—because they were literally trained on that literature. That knowledge is being deployed not to simulate humans, but to simulate the methodological scrutiny that expert reviewers would apply if you had unlimited budget to hire them.
The Validation Protocol
The empirical test is simple. Take twenty real surveys that went through traditional human pilot testing. Retroactively run them through the synthetic audit. Compare what the synthetics flagged versus what the human pilots found.
Your metrics are precision (what percentage of synthetic warnings were real problems?) and recall (what percentage of real problems did the synthetics catch?). Initial studies suggest precision around sixty to seventy percent and recall around seventy to eighty percent. That’s not perfect. But it’s good enough to be useful at one percent of the cost.
The false positives—where synthetics flag a problem that humans didn’t find—become a secondary research question. Sometimes the synthetics are wrong. Sometimes they catch subtle biases that humans, embedded in the same cultural context as the question-writers, simply didn’t notice. You investigate. You decide. You’re still in control.
The convergent validity test is more ambitious: Create two versions of a survey measuring stigmatized attitudes. Version A uses standard question development with human pilots. Version B uses synthetic audit first, then one human pilot. Field both to separate random samples. Compare: Which version shows lower social desirability scale correlations? Which version’s responses correlate more strongly with behavioral measures? If Version B wins, the synthetic audit improved measurement quality. If Version A wins, you’ve learned the limits of the method.
The Economic Proposition
The survey research industry represents billions in annual spending. If synthetic audits can reduce pre-testing costs by even twenty percent while improving question quality by five percent, the value creation is substantial. Not because synthetics replace humans, but because they make human research more efficient.
You’re still doing the human survey. You’re still measuring private opinion that text analysis and behavioral data cannot capture. You’re still anchoring your findings in the lived experience of actual people, randomly sampled, whose internal mental states you’re attempting to map with imperfect but irreplaceable instruments.
You’re just making sure, before you spend forty-seven thousand dollars, that your thermometer is calibrated as well as you can calibrate it.
The button is still waiting. The contract is still ready to sign. But now you run the audit first. Forty-seven dollars. Twenty minutes. A list of warnings that might save your study.
You press “audit” instead of “approve.”
The questions that survive that filter—the ones that don’t trigger social desirability cascades, that don’t confuse high and low education respondents differently, that don’t activate stereotypes instead of measuring genuine variance—those questions earn their place in the forty-seven thousand dollar instrument.
And somewhere in that dataset, the finding that matters might actually emerge. Not because you asked more people. Because you asked them correctly.