
What is Computational Skepticism?
When AI can fabricate claims in seconds but verification takes days, truth loses by attrition. Here's how to fight back.


What is Computational Skepticism?
September 25, 2025. The Government Accountability Office issues a decision that will reshape how federal agencies handle AI-generated legal filings. Case number B-423649. Oready, LLC versus the United States government.
The company had filed multiple bid protests—a critical mechanism for holding procurement agencies accountable when they award contracts improperly. But something was wrong with these filings. The citations looked perfect: proper Bluebook format, confident legal prose, specific GAO decisions quoted verbatim to support each argument.
None of them existed.
The case names were fabricated. The holdings were invented. The legal principles were fiction. The GAO dismissed the protests as an “abuse of process” and issued a warning that would echo across the federal system: while the use of AI is not prohibited, “reckless disregard for accuracy” will not be tolerated.
This was not the first incident. In May 2025, Raven (B-423524) admitted its erroneous citations were AI-generated. In July, BioneX (B-423630) submitted filings with citations bearing “hallmarks of AI cases.” In August, IBS Government Services (B-423583) filed briefs containing fabricated or misquoted GAO decisions. By September, the pattern was undeniable: federal procurement—a system designed for careful deliberation—was being overwhelmed by high-fluency legal fiction generated in seconds.
This is not an outlier problem. This is the new normal.
You are living through the collapse of a fundamental relationship: the relationship between the cost of producing a claim and the cost of verifying it.
The Asymmetry
In 2013, an Italian programmer named Alberto Brandolini made an observation about internet arguments that has become known as Brandolini’s Law: “The amount of energy needed to refute bullshit is an order of magnitude larger than is needed to produce it.”
At the time, it was a wry comment about online debate. Today, it is the defining crisis of the information age.
Consider the mathematics:
These ratios are not estimates. They are measurements from academic research, legal systems, and financial auditing. A disinformation video takes fifteen minutes to produce: script, voiceover, stock footage, upload. The refutation—consulting subject matter experts, transcribing interviews, fact-checking each claim, drafting a legible response—takes three days. That is a ratio of 1:288.
An LLM-generated medical abstract claiming a breakthrough drug reduced mortality by 40 percent takes thirty seconds to write. Verifying that claim requires accessing the raw data, rerunning the statistical analysis, consulting with clinicians, and checking for p-hacking. Three to five days minimum. The ratio exceeds 1:10,000.
Large Language Models optimize for the statistical probability of a sequence of tokens, not for truth. They hallucinate—producing likely but false statements—at rates estimated near 30 percent in complex domains like procurement law. The marginal cost of producing persuasive, high-fluency nonsense has approached zero. The marginal cost of verification remains tethered to human cognitive processing, institutional review, and the stubborn limits of time.
This divergence creates what researchers call the “implied truth effect”: unchallenged misinformation gains perceived accuracy simply by escaping refutation. By the time you have carefully dismantled one claim, it has already spread, forked, mutated, and emotionally landed. The audience has moved on. The correction arrives too late.
The institutions designed for verification—peer-reviewed journals, judicial systems, regulatory bodies—were built for a world where friction constrained production. They assumed the cost of generating a claim was high enough to filter out low-quality submissions. That assumption is dead.
When the cost of production is zero, volume scales beyond human capacity to monitor. This is not a bug. This is a denial-of-service attack on truth itself.
The Veneer
The most dangerous form of bullshit is not the obvious lie. It is the claim that wears what researchers call “the veneer of rigor.”
You see it everywhere now: AI-generated content that mimics the structural markers of expertise. LaTeX equations. Regression tables with t-statistics and confidence intervals. P-values gleaming at 0.049. Charts with error bars. Footnotes citing non-existent papers with plausible-sounding titles. The cognitive load is already high. You are reading quickly. The format performs the work of legitimacy. You move on.
In medicine, this manifests as synthetic manuscripts that achieve similarity scores between 14 and 26 percent on plagiarism detection software—far below the thresholds that trigger automatic rejection—while being entirely fabricated in their findings. These papers pass the formatting check. They survive the similarity scan. They enter the literature. Other AI systems cite them. The loop closes.
In finance, AI-driven trading strategies report “surprising” alpha—excess returns above the market—until you realize the model is predicting the past using information from the future. This is called look-ahead bias, a form of temporal contamination where the model has been trained on web-scale datasets that include post-hoc explanations of market events. When the LLM “forecasts” a stock’s performance during a historical period it was trained on, it is not reasoning. It is reciting.
In law, the fabricated GAO decisions in the Oready case were formatted perfectly. Proper case citations. Bluebook-compliant parentheticals. Confident holdings that appeared to support the legal argument. The only problem: they were ghosts. The cases did not exist. But the format was indistinguishable from legitimate legal work.
This is authority laundering. The automated output is accepted as an expert finding because it is dressed in the costume of expertise. The human brain, confronted with these structural cues, defaults to trust. We are pattern-matching machines, and the pattern of expertise is easier to recognize than the absence of substance.
You cannot fact-check your way out of this problem. The volume is too high. The fluency is too good. The veneer is too convincing.
The Response
If bullshit production has been automated, skepticism must also be automated.
This is not a metaphor. This is the operational thesis of computational skepticism: build cheap, fast, structural checks that reduce the cost of verification and introduce friction into persuasion before belief sets in.
Computational skepticism is not a new philosophy. It is the application of a very old philosophy to a radically new problem. The intellectual lineage runs through:
Karl Popper: Knowledge advances by disproving claims, not defending them. A theory that cannot be falsified is not scientific—it is unfalsifiable, and therefore useless.
David Hume: Induction is fragile. No amount of confirming observations proves a universal claim. One black swan falsifies “all swans are white.”
Harry Frankfurt: Bullshit is more corrosive to truth than lying. The liar knows what truth is and deliberately inverts it. The bullshitter does not care about truth at all—only about the effect of the speech.
Daniel Kahneman: Systematic error is more dangerous than random ignorance. Our cognitive biases—fast thinking, confirmation bias, availability heuristic—make us predictably wrong in specific ways.
Richard Feynman: The first principle is that you must not fool yourself—and you are the easiest person to fool.
The rule, inherited from Popper, is simple: A claim that cannot be stress-tested is not knowledge—it is marketing.
Computational skepticism applies this rule at machine speed.
The Toolkit
You do not need to reinvent epistemology. You need to lower the cost of verification.
1. Baselines and Null Models
A result is only meaningful if it outperforms a null model—a representation of the system where the hypothesized effect is absent.
Imagine a financial AI system claims it can predict stock returns with 65 percent accuracy. Impressive, until you ask: what is the baseline? What does a random walk predict? What does a simple moving average predict? If the complex AI model achieves 65 percent and the moving average achieves 63 percent, the additional complexity is buying you two percentage points. That is not alpha. That is noise.
Strip the rhetoric. Ask: could this outcome be achieved with linear regression? If yes, the rest is overfitting dressed as insight.
2. Statistical Fingerprints
Real-world data possesses universal properties that are difficult for synthetic systems to replicate.
Natural datasets—whether images, text, or tabular data—exhibit a characteristic power-law decay of eigenvalues in their covariance matrices:
λᵢ ∝ i⁻ᵅ
Where λᵢ is the i-th eigenvalue and α is the decay exponent. This pattern holds across modalities: financial time series, genomic sequences, sensor readings. It is a signature of complex systems with hierarchical structure.
Synthetic data, while mimicking basic statistics like mean and variance, often fails to replicate these higher-order spectral properties. The eigenvalues drop too sharply or flatten in unnatural ways. The correlation structure is artificially smoothed. By treating data as a physical system and employing tools from Random Matrix Theory, you can identify when a model is memorizing training data rather than learning underlying patterns.
The artificial records leak information through dense regions in the data manifold—what researchers call “medoid” clusters. These clusters approximate the original training data, revealing that the model has not generalized. It has memorized.
3. Perturbation and Fragility
A robust claim should remain stable under slight changes to its inputs. Bullshit is fragile.
Introduce noise. Rephrase the question slightly. Shift a parameter by five percent. If the model’s conclusion shifts wildly, the initial claim is not robust—it is a hallucination.
In Retrieval-Augmented Reasoning systems, this method is called R2C (Retrieval-Augmented Reasoning Consistency). The system is asked the same question multiple times with slight variations in phrasing or with different intermediate reasoning steps. If the final answers are consistent, the system has high confidence and low uncertainty. If the answers diverge dramatically, the system is guessing.
The mathematical representation is cross-entropy between the model’s predictive distribution and the true distribution. High divergence across perturbed paths reveals that the claim is sitting on a knife’s edge. It will collapse under scrutiny.
The Audits
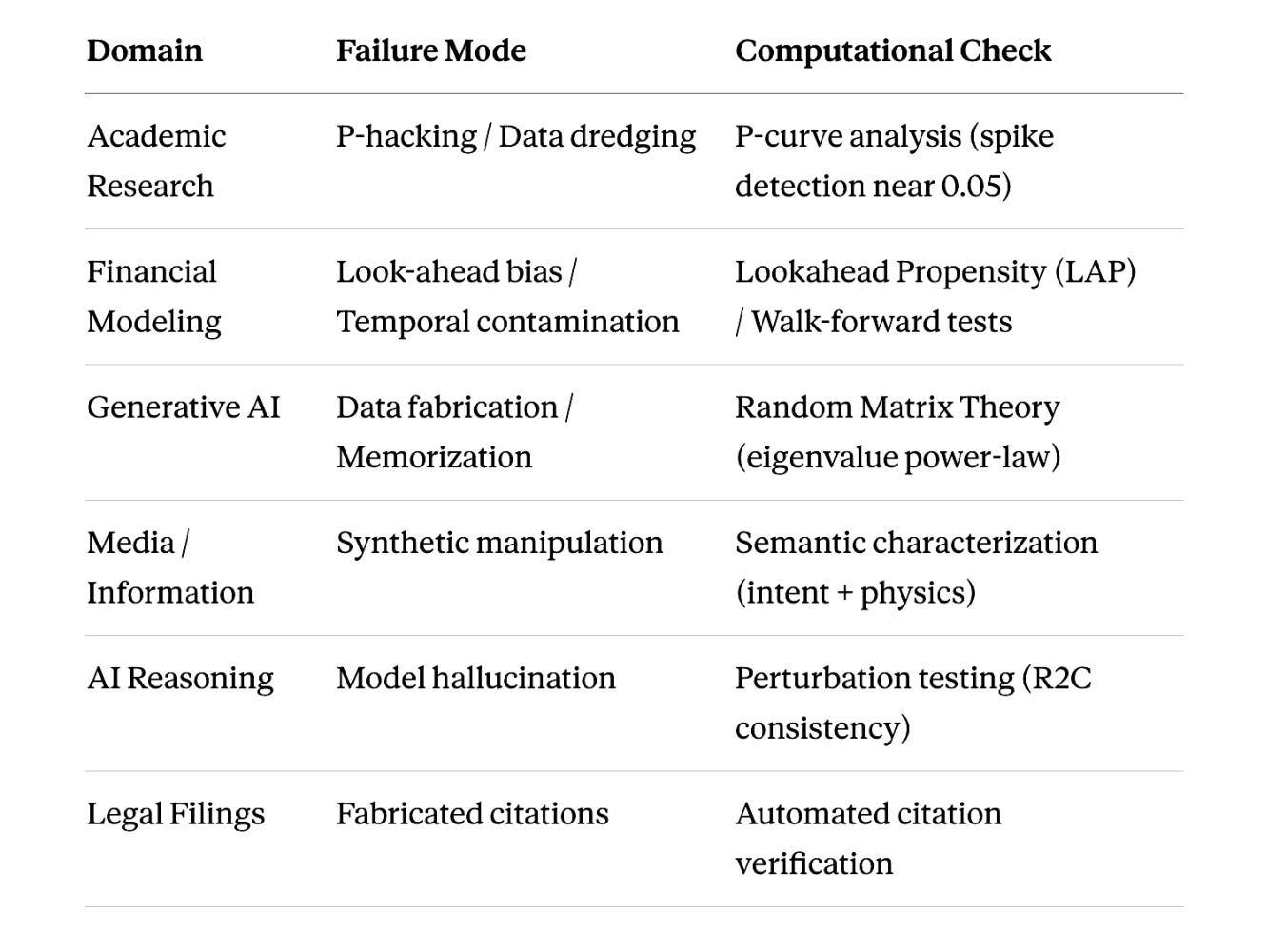
These are not theoretical exercises. They are operational methods deployed in medicine, finance, law, and media.
Medicine: The P-Curve
You are reviewing a medical study. The abstract promises a new intervention reduces mortality by 40 percent. The p-value gleams at 0.049. Just below the magic threshold of 0.05 that separates “statistically significant” from “not publishable.”
This should make you suspicious.
In a system without p-hacking, the distribution of p-values across a set of studies should be right-skewed. If the null hypothesis is true—if there is no real effect—p-values are uniformly distributed between 0 and 1. If a genuine effect exists, the density increases as p approaches zero. You get lots of very small p-values: 0.001, 0.003, 0.008.
But when you see a spike at p = 0.049? At p = 0.048? Clustering just below 0.05?
That is the fingerprint of p-hacking. Researchers ran twenty different statistical tests and published the one that crossed the threshold. They “sliced and diced” the data—testing different subgroups, different time windows, different outcome measures—until something worked. GenAI has amplified this problem by enabling researchers to generate hundreds of analyses in seconds and cherry-pick the one that looks significant.
Computational check: Automate p-curve analysis. Aggregate the p-values from every study in a research domain. Plot the distribution. A spike just below 0.05 is a structural red flag. The studies should be audited. The weak claims collapse before they reach the press release stage.
Finance: Alpha Decay and Look-Ahead Bias
You are evaluating an AI-driven trading strategy. The backtest results are impressive: 12.4 percent alpha over the past three years. The system claims it is learning market microstructure and predicting momentum reversals.
This should also make you suspicious.
Financial LLMs are trained on web-scale datasets that include news articles, analyst reports, and retrospective explanations of market events. When the model “predicts” what happened in 2022, it has often already seen the answer in its training data. It is not forecasting. It is reciting.
The Look-Ahead-Bench benchmark measures “alpha decay”—the performance drop when a model moves from periods it was trained on to genuinely unknown territory:
Llama 3.1 70B: +12.4% alpha during the training window. -3.2% alpha in the out-of-sample period. Alpha decay: -15.6 percentage points.
DeepSeek 3.2: +10.8% in-sample. -2.1% out-of-sample. Alpha decay: -12.9 percentage points.
Compare this to models designed with point-in-time constraints—systems explicitly prevented from peeking into the future:
PiT-Inference (Small): +4.1% in-sample. +3.9% out-of-sample. Alpha decay: -0.2 percentage points.
The larger the standard model, the stronger its in-sample memorization—and the more catastrophic its collapse in unknown data. This is inverse scaling. The “smarter” the model appears during training, the worse it performs when the crutch of memorization is removed.
Computational check: Lookahead Propensity (LAP). Measure the correlation between model familiarity with training data and forecast accuracy. Enforce code-level safeguards: use confirmed closed-bar values, not real-time values. Mandate walk-forward tests on data the model has never seen. If alpha does not persist, the performance is temporal contamination, not skill.
Media: Semantic Forensics
You are looking at a photograph. The lighting is perfect. The skin texture is flawless. The composition is professional. But something is wrong.
The earrings do not match. The reflection in the subject’s eyes shows a light source that does not exist in the room. The shadow angle contradicts the metadata timestamp. An infographic chart embedded in the background contradicts the article text beneath the image.
These are not pixel errors. These are failures of meaning.
The DARPA Semantic Forensics (SemaFor) program addresses this problem through “forensic semantic technologies” that identify inconsistencies across multiple modalities. The system does not just ask: “Is this image synthetic?” It asks: “Does this image make semantic sense?”
A GAN-generated face might pass pixel-level statistical tests. But when you check whether the multi-modal assets—text, audio, image—exhibit coherent physical reality, the failures appear. Light sources that violate physics. Reflections that show impossible scenes. Text that contradicts the visual content.
Computational check: Semantic characterization. Analyze images not in isolation but in context with accompanying text, metadata, and claimed provenance. Flag physical impossibilities. Identify intent by tracing the distribution pattern and the rhetorical framing. User studies show that revealing the underlying agenda behind synthetic media—”This image was generated to support a specific narrative about X”—is more effective than simple “AI-generated” tags in helping audiences form informed interpretations.
People trust visual information. Revealing the intent is as critical as identifying the synthetic origin.
Law: Professional Standards in the Age of Automation
The GAO’s decision in Oready establishes a new professional standard: AI-assisted work must meet the same ethical and factual requirements as human work. The veneer of rigor—formatted briefs, confident prose, proper citations—no longer provides cover for fabrication.
Judges and tribunals across jurisdictions are issuing similar warnings. In New York, sanctions have been imposed on attorneys who submitted briefs containing fabricated case law generated by ChatGPT. The legal profession is adapting faster than most because the consequences of failure are immediate and traceable: cases are dismissed, sanctions are imposed, licenses are at risk.
Computational check: Citation verification systems. Automated tools that cross-reference every cited case against legal databases in real-time, flagging non-existent citations before filings are submitted. These systems are now being integrated into legal research platforms as a prophylactic measure against hallucination.
The Framework
The goal is not to create a world of blanket distrust. It is to restore human agency in a high-noise environment.
This requires building skeptical principles into the architecture of AI systems themselves.
Consider the Popper Framework—an agentic system designed for the rigorous automated validation of free-form hypotheses. It is named after Karl Popper and operates on his principle of falsification.
The system deploys two primary agents:
Experiment Design Agent: Identifies measurable implications of a hypothesis and designs falsification experiments.
Experiment Execution Agent: Implements those experiments through Python code, simulations, or data analysis. Produces statistical evidence.
The critical innovation: Popper converts individual p-values into e-values—a statistical framework that allows for the aggregation of evidence from multiple, potentially dependent tests while strictly controlling Type-I error rates. This enables “any-time valid” sequential testing. The system can decide at any point whether to reject a hypothesis, accept it provisionally, or gather more evidence—without inflating false positive rates through multiple testing.
Compared to human scientists working through the same validation process, the Popper Framework achieves comparable performance while reducing time required by ten-fold.
The system operationalizes three core principles:
Evidence-based claims: Systematically evaluate every assertion by balancing supporting and contradicting evidence. Do not cherry-pick.
Falsification testing: Actively attempt to disprove assumptions rather than merely confirm them. Look for disconfirming evidence.
Causal validation: Verify that relationships are causal, not coincidental. Use Evidence Knowledge Graphs and Directed Acyclic Graphs to model causal structure and test counterfactuals.
By automating these layers, you shift the responsibility of skepticism from the overwhelmed human to the computational framework. You restore balance to the asymmetry.
The Literacy
This requires a new form of literacy. Call it AI Fluency or Botspeak—the ability to work effectively with AI systems while maintaining critical evaluation at every step.
AI fluency involves understanding:
Strategic delegation: When to delegate tasks to AI based on comparative strengths. AI excels at pattern matching, retrieval, and generation at scale. Humans excel at normative judgment, contextual interpretation, and semantic coherence.
Critical evaluation: How to assess outputs for accuracy, bias, and hallucination. Never accept AI output at face value. Every claim is a hypothesis to be tested.
Stochastic reasoning: How to think probabilistically rather than deterministically. LLMs are statistical systems. They do not “know” facts—they predict token sequences. Understanding this changes how you interpret their outputs.
The professional standard is emerging: if you use AI to assist your work, you are accountable for verifying its outputs. “The AI made a mistake” is not a defense. This is the Ethical No-Free-Lunch principle: human normative intervention and accountability are indispensable in any AI-assisted decision-making process.
The Imperative
You are standing at the threshold of a transition. The epistemic relationship between information and verification has fundamentally shifted. The cost of production has collapsed. The cost of refutation has not.
This is the asymmetry. It is not ideological. It is structural. And it is solvable.
DomainFailure ModeComputational CheckAcademic ResearchP-hacking / Data dredgingP-curve analysis (spike detection near 0.05)Financial ModelingLook-ahead bias / Temporal contaminationLookahead Propensity (LAP) / Walk-forward testsGenerative AIData fabrication / MemorizationRandom Matrix Theory (eigenvalue power-law)Media / InformationSynthetic manipulationSemantic characterization (intent + physics)AI ReasoningModel hallucinationPerturbation testing (R2C consistency)Legal FilingsFabricated citationsAutomated citation verification
Computational skepticism does not outsource judgment to machines. It lowers the cost of verification so humans can apply judgment where it matters. It introduces friction into persuasion before belief sets in. It treats every AI output as a hypothesis to be stress-tested.
The medical study promising 40 percent mortality reduction must be verified within three days. The researcher who manufactured it did so in thirty seconds. The financial backtest showing 12 percent alpha must be walk-forward tested on unknown data. The model that generated it was trained on the answer. The legal brief citing five GAO decisions must be checked against the actual case law. The LLM that wrote it hallucinated all five citations.
Unless skepticism is automated—unless we build structural friction into information systems at the same scale as generation—the asymmetry will prevail.
The central rule remains: A claim that cannot be subjected to a cheap, fast, structural check is not knowledge—it is marketing.
The institutions are adapting. The GAO dismisses fabricated filings. Judges impose sanctions. Medical journals implement pre-registration. Financial regulators mandate out-of-sample testing. The DARPA program develops semantic forensics.
But the tools must scale. The checks must be computationally cheap. The friction must be structural, not manual.
The choice is not moral. It is operational. The cost of verification must approach the cost of generation, or truth loses by attrition.
The tools exist. The frameworks are built. The professional standards are emerging.
The future of truth depends on the rigorous application of doubt.
This is a great perspective. I particularly liked the focus on Semantic Forensics and the 'Ethical No-Free-Lunch' principle. It moves the conversation beyond just 'detecting AI' and toward maintaining actual human accountability in a high-noise environment.
The line that sticks: "truth loses by attrition." Not by argument, not by being wrong — just by being too expensive to defend. That reframes the whole problem.